Qualche giorno fa ho avuto uno spunto di riflessione parlando con il mio allenatore, il quale mi ha detto che le persone dell'est sono più facilmente allenabili di un italiano perché hanno una mentalità più rigida e si impegnano molto di più per fare quello che il proprio allenatore gli suggerisce.
Questo mi ha fatto riflettere.
Penso che noi italiani, proprio per la nostra mentalità e carattere, tendiamo a fidarci di più del risultato che non delle parole del nostro allenatore. Non ci poniamo il dubbio se quello che ci viene suggerito serva realmente a fare punti, ci facciamo invece distrarre dal risultato e, essendo sempre alla ricerca dei che possono farci fare qualche trucco per fare un giallo in più, tendiamo a pensare di essere più furbi del nostro allenatore. Anche perché spesso tirare bene è scomodo, almeno in un primo tempo, rispetto a tirare nel modo più naturale (e spesso sbagliato). E allora la sfiducia (passatemi il termine) nel nostro allenatore aumenta.
Invece l'allenatore con la sua esperienza e la sua pazienza è un valido sostegno e aiuto per migliorare costantemente. Fidiamoci quindi dei nostri allenatori!
martedì 23 dicembre 2008
Dependency Injection: costruttori o setter?
La Dependency Injection (DI) viene spesso realizzata mediante uno o più parametri passati al costruttore di un oggetto, ad esempio se una classe ha bisogno di sapere il suo DAO, quest'ultimo può essere passato al costruttore dell'oggetto.
Esiste un lungo dibattito su cosa sia meglio fare per permettere la DI, in particolare se sia meglio usare un costruttore o dei metodi setter. Il vantaggio nell'uso di un costruttore consiste nel fatto che l'oggetto ottenuto è sempre inizializzato correttamente, e quindi non è possibile lasciare in uno stato parziale l'oggetto (ossia tutte le sue dipendenze devono essergli iniettate prima che l'oggetto sia costruito). Il vantaggio nell'uso dei setter è quello di avere la possibilità di riconfigurare l'oggetto in ogni momento, ma si corre il rischio di lasciare l'oggetto non inizializzato correttamente. Da quanto appena detto si evince che l'uso dei costruttori è generalmente quello migliore e quindi quello più consigliato.
Tuttavia esiste un problema nell'uso del costruttore per DI che si verifica nel caso in cui l'oggetto che si sta costruendo abbia molte dipendenze, o abbia necessità di ricevere molti parametri: la signature del costruttore diventa inevitabilmente lunga e quindi di difficile utilizzo e comprensione. Si noti poi che non è consigliato implementare dei setter da usare nel costruttore per realizzare, in un sol colpo, entrambi i metodi di DI, poiché i setter saranno (generalmente) polimorfici, e l'uso di metodi polimorfici nei costruttori è fortemente sconsigliato.
Quindi che soluzione adottare? L'unica che mi sento di consigliare è di usare il costruttore quando si hanno pochi parametri (3,4 al massimo) e di passare a metodi setter per un numero di parametri maggiore. E' comunque bene dare la priorità al costruttore, specificando nella sua signature tutti i parametri DI di maggior importanza, così che l'oggetto non possa essere costruito senza di essi. Infine, occorre informare l'utente in modo chiaro e preciso attraverso la documentazione di tutte le dipendenze e della loro importanza per l'inizializzazione dell'oggetto. Una possibile soluzione per forzare una completa inizializzazione dell'oggetto mantenendo la signature del costruttore corta, o implementando i setter, consiste nell'uso di un costruttore privato e di un metodo factory per ottenere l'istanza. In questo modo il metodo factory può utilizzare tutti i setter per inizializzare opportunamente l'oggetto da restituire.
Esiste un lungo dibattito su cosa sia meglio fare per permettere la DI, in particolare se sia meglio usare un costruttore o dei metodi setter. Il vantaggio nell'uso di un costruttore consiste nel fatto che l'oggetto ottenuto è sempre inizializzato correttamente, e quindi non è possibile lasciare in uno stato parziale l'oggetto (ossia tutte le sue dipendenze devono essergli iniettate prima che l'oggetto sia costruito). Il vantaggio nell'uso dei setter è quello di avere la possibilità di riconfigurare l'oggetto in ogni momento, ma si corre il rischio di lasciare l'oggetto non inizializzato correttamente. Da quanto appena detto si evince che l'uso dei costruttori è generalmente quello migliore e quindi quello più consigliato.
Tuttavia esiste un problema nell'uso del costruttore per DI che si verifica nel caso in cui l'oggetto che si sta costruendo abbia molte dipendenze, o abbia necessità di ricevere molti parametri: la signature del costruttore diventa inevitabilmente lunga e quindi di difficile utilizzo e comprensione. Si noti poi che non è consigliato implementare dei setter da usare nel costruttore per realizzare, in un sol colpo, entrambi i metodi di DI, poiché i setter saranno (generalmente) polimorfici, e l'uso di metodi polimorfici nei costruttori è fortemente sconsigliato.
Quindi che soluzione adottare? L'unica che mi sento di consigliare è di usare il costruttore quando si hanno pochi parametri (3,4 al massimo) e di passare a metodi setter per un numero di parametri maggiore. E' comunque bene dare la priorità al costruttore, specificando nella sua signature tutti i parametri DI di maggior importanza, così che l'oggetto non possa essere costruito senza di essi. Infine, occorre informare l'utente in modo chiaro e preciso attraverso la documentazione di tutte le dipendenze e della loro importanza per l'inizializzazione dell'oggetto. Una possibile soluzione per forzare una completa inizializzazione dell'oggetto mantenendo la signature del costruttore corta, o implementando i setter, consiste nell'uso di un costruttore privato e di un metodo factory per ottenere l'istanza. In questo modo il metodo factory può utilizzare tutti i setter per inizializzare opportunamente l'oggetto da restituire.
venerdì 19 dicembre 2008
Creare le share personalizzate per ogni utente in Samba (con LDAP)
Invece che utilizzare la classica share homes di Samba, ho installato su un server una condivisione personalizzata chiamata MyDoc, che deve essere esclusiva di ogni utente. Per fare questo occorre che la share punti sempre ad una cartella di proprietà esclusiva dell'utente che ha effettuato il login, cosa abbastanza semplice da realizzare tramite le variabili messe a disposizione da Samba, nel caso specifico %U (utente di login):
[MYDOC_SMB]
comment = Cartella documenti personalizzati per utenti
path = /mnt/samba/mydoc_smb/%U
browsable = yes
available = yes
writable = yes
printable = no
copy = perm_template
valid users = %U
A questo punto occorre però creare le cartelle di ogni singolo utente, che devono avere come nome il relativo login, e assegnare i diritti a tutte le cartelle in modo che siano di proprietà esclusiva dell'utente stesso. Su un sistema con OpenLDAP è possibile eseguire il seguente script per ottenere lo scopo:
In sostanza tramite ldapsearch si va a cercare ogni utente nel sistema, dopdoiché si effettua una ricerca per trovare i gruppi a cui questo utente appartiene. Siccome un utente può appartenere a più gruppi, come scelta implementativa si tiene valido l'ultimo gruppo trovato. Viene creata la directory e vengono impostati i permessi e il proprietario della directory stessa.
[MYDOC_SMB]
comment = Cartella documenti personalizzati per utenti
path = /mnt/samba/mydoc_smb/%U
browsable = yes
available = yes
writable = yes
printable = no
copy = perm_template
valid users = %U
A questo punto occorre però creare le cartelle di ogni singolo utente, che devono avere come nome il relativo login, e assegnare i diritti a tutte le cartelle in modo che siano di proprietà esclusiva dell'utente stesso. Su un sistema con OpenLDAP è possibile eseguire il seguente script per ottenere lo scopo:
#!/bin/bash
SEARCH_CMD=`which ldapsearch`
SEARCH_OPTIONS=" -x uid "
GREP_CMD=`which grep`
GREP_OPTIONS=" uid:"
AWK_CMD=`which awk`
AWK_OPTIONS="'{print \$2;}' "
EVAL_CMD="eval"
MKDIR_CMD=`which mkdir`
MKDIR_OPTIONS=" -p "
MYDOC_ROOT="/mnt/samba/mydoc_smb"
CHOWN_CMD=`which chown`
CHMOD_CMD=`which chmod`
CHMOD_OPTIONS=" 777 "
SUCCESSES=0
FAILURES=0
for utente in `$EVAL_CMD "$SEARCH_CMD $SEARCH_OPTIONS | $GREP_CMD $GREP_OPTIONS | $AWK_CMD $AWK_OPTIONS" `
do
# devo ottenere il gruppo di questo utente
SEARCH_OPTIONS_2=" -x \"(&(objectClass=posixGroup)(memberUid=$utente))\" "
GREP_OPTIONS_2=" cn: "
echo -en "Processo utente <$utente>..."
dstDir=${MYDOC_ROOT}/${utente}
$MKDIR_CMD $MKDIR_OPTIONS $dstDir > /dev/null 2>&1
if [ $? -eq 0 ]
then
echo -en "ok\n"
# devo cambiare il proprietario della directory. Siccome la directory potrebbe
# contenere piu' gruppi, devo ciclare su ognuno e assegno i permessi dell'ultimo gruppo.
for gruppo in `$EVAL_CMD "$SEARCH_CMD $SEARCH_OPTIONS_2 | $GREP_CMD $GREP_OPTIONS_2 | $AWK_CMD $AWK_OPTIONS" `
do
$CHOWN_CMD $utente:$gruppo $dstDir > /dev/null 2>&1
done
$CHMOD_CMD $CHMOD_OPTIONS $dstDir > /dev/null 2>&1
SUCCESSES=$(( SUCCESSES + 1 ))
else
echo -en "KO\n"
FAILURES=$(( FAILURES + 1 ))
fi
done
echo -en "\n\n\nFinito:\n\t $SUCCESSES processati correttamente,\n\t $FAILURES falliti\n"
In sostanza tramite ldapsearch si va a cercare ogni utente nel sistema, dopdoiché si effettua una ricerca per trovare i gruppi a cui questo utente appartiene. Siccome un utente può appartenere a più gruppi, come scelta implementativa si tiene valido l'ultimo gruppo trovato. Viene creata la directory e vengono impostati i permessi e il proprietario della directory stessa.
mercoledì 17 dicembre 2008
Modificare automaticamente la data di scadenza password su Ubuntu/Samba-LDAP
Se si ha un sistema di gestione account basato su LDAP tramite gli smbldap tools è possibile editare automaticamente tutti gli account per modificare la data di scadenza password. Il seguente script accetta come parametro (opzionale) un numero di anni per i quali la password non deve scadere, dopodiché calcola la data di nuova scadenza della password e ricerca tutti gli utenti (Users) nel sistema LDAP per poi modifcarne la data di scadenza tramite smbldap-usermod:
Si noti che siccome la ricerca dei vari uid avviene tramite una ricerca ldap, filtrata da awk, occorre usare un eval per l'esecuzione del comando per impedire alla shell di interpretare male i caratteri di comando awk.
Lo script di cui sopra mostra poi il risultato della sua esecuzione informando l'utente del numero di utenti modificati e di quelli in cui il comando è fallito.
Sebbene sia consigliabile la modifica delle password periodica, un simile script è utile per quegli ambienti dove gli utenti si autenticano in modo automatico tramite chiavi SSH, e quindi dove non sono interessati a mantenere la propria password che può quindi essere modificata in automatico da un amministratore o da una procedura automatizzata.
#!/bin/bash
# considero che incremento di anno ho, se non ne ho nessuno
# allora incremento di default di 4 anni
YEAR_INCREMENT=$1
if [ -z "$YEAR_INCREMENT" ]
then
YEAR_INCREMENT=4
fi
DATE_CMD=`which date`
CURRENT_YEAR=`$DATE_CMD +'%Y'`
FINAL_YEAR=$(( CURRENT_YEAR + YEAR_INCREMENT ))
EXPIRE_DATE="${FINAL_YEAR}-12-31"
echo "Verra' impostata la data di password expiration per $EXPIRE_DATE"
PWD_CMD=`which smbldap-usermod`
PWD_OPTIONS=" --shadowExpire $EXPIRE_DATE --shadowMax 700"
SEARCH_CMD=`which ldapsearch`
SEARCH_OPTIONS=" -x uid "
GREP_CMD=`which grep`
GREP_OPTIONS=" uid:"
AWK_CMD=`which awk`
AWK_OPTIONS="'{print \$2;}' "
EVAL_CMD="eval"
SUCCESSES=0
FAILURES=0
for utente in `$EVAL_CMD "$SEARCH_CMD $SEARCH_OPTIONS | $GREP_CMD $GREP_OPTIONS | $AWK_CMD $AWK_OPTIONS" `
do
echo -en "Processo utente <$utente>..."
$PWD_CMD $PWD_OPTIONS $utente > /dev/null 2>&1
if [ $? -eq 0 ]
then
echo -en "ok\n"
SUCCESSES=$(( SUCCESSES + 1 ))
else
echo -en "KO\n"
FAILURES=$(( FAILURES + 1 ))
fi
done
echo -en "\n\n\nFinito:\n\t $SUCCESSES processati correttamente,\n\t $FAILURES falliti\n"
Si noti che siccome la ricerca dei vari uid avviene tramite una ricerca ldap, filtrata da awk, occorre usare un eval per l'esecuzione del comando per impedire alla shell di interpretare male i caratteri di comando awk.
Lo script di cui sopra mostra poi il risultato della sua esecuzione informando l'utente del numero di utenti modificati e di quelli in cui il comando è fallito.
Sebbene sia consigliabile la modifica delle password periodica, un simile script è utile per quegli ambienti dove gli utenti si autenticano in modo automatico tramite chiavi SSH, e quindi dove non sono interessati a mantenere la propria password che può quindi essere modificata in automatico da un amministratore o da una procedura automatizzata.
lunedì 15 dicembre 2008
Call vs Execution Join Point
Si sente spesso parlare di differenza fra i join point di call e di execution, tanto che la domanda è molto spesso fatta da chi è alle prime armi con l'AOP e AspectJ. Per chiarezza occorre ricordare che mentre un call "osserva" il codice dal lato chiamante (quindi un this punta all'oggetto che invoca un metodo), un execution "osserva" il codice dal lato chiamato (quindi un this punta all'oggetto sul quale il metodo è invocato). Tuttavia esiste un'ulteriore differenza, sottile e subdola e che potrebbe lasciare sconcertati quando si utilizza la reflection: un execution join point, dovendo essere sul lato del codice chiamato, viene sempre messo inline con il codice stesso. Questo significa che anche se la chiamata al metodo avviene tramite reflection il join-point verrà processato. Diverso il caso invece per call, che non può essere messo inline (si avrebbe un contesto differente) e che quindi viene normalmente bypassato dall'uso della reflection. In altre parole, se si vuole gestire un join point di tipo call occorre prevedere tutte le chiamate dirette al metodo e anche quelle che eventualmente vengono fatte tramite reflection.
venerdì 5 dicembre 2008
Gestire un database PostgreSQL mediante Eclipse
Eclipse è un ambiente di sviluppo veramente completo, che consente anche il collegamento a diverse origini dati, fra le quali database SQL. In questo articolo mostrerò come collegare un database PostgreSQL ad Eclipse, in modo che sia possibile amministrare e ispezionare i dati direttamente dall'IDE senza dover appoggiarsi a tool esterni.
Eclipse basa la sua connettività database su JDBC, e quindi è necessario aver scaricato ed installato un driver opportuno dal sito del progetto JDBC di PostgreSQL.
Supponendo di voler collegare un database di nome hrpmdb che risiede sull'host sedeldap i passi da eseguire sono i seguenti:








Eclipse basa la sua connettività database su JDBC, e quindi è necessario aver scaricato ed installato un driver opportuno dal sito del progetto JDBC di PostgreSQL.
Supponendo di voler collegare un database di nome hrpmdb che risiede sull'host sedeldap i passi da eseguire sono i seguenti:
- dal menù Windows selezionare la voce Open view e quindi Others. Dalla finestra di dialogo che si apre cercare la categoria Connectivity e quindi Data source explorer.
- Nella nuova vista che si apre, fare click con il tasto destro del mouse sulla voce Databases e quindi selezionare New.
- Si apre una finestra di dialogo dalla quale selezionare il tipo di database, che ovviamente è PostgreSQL. Occorre anche dare un nome simbolico a questa connessione e una descrizione (opzionale) della connessione stessa.

- Nella finestra successiva occorre indicare il driver JDBC da usare per la connessione. Se non si è installato ancora nessun driver, occorre cliccare sul pulsante a fianco del menù a discesca e andare a ricercare il driver da installare. In particolare nella dialog che si apre occorre andare nel tab jar list, aggiungere il file jar contenente il driver e quindi tornare al tab principale per confermare l'installazione del driver.



- A questo punto è possibile tornare alla configurazione della connessione e impostare tutti i parametri, quali URL (che deve essere nella forma JDBC e quindi con jdbc:postgres://).

- A questo punto la connessione compare nella view delle sorgenti di dati, ed è possibile esplorare la struttura del database a cui si è connessi.

- E' infine possibile accedere ed editare i dati di una tabella selezionando dal menù contestuale Data->Edit e agendo sull'editor che viene aperto con il contenuto della tabella selezionata.


mercoledì 19 novembre 2008
Importare un progetto SVN in Eclipse gestendolo con Git
Al fine di meglio apprendere Git, il sistema di gestione dei sorgenti appositamente sviluppato per il Kernel di Linux (ma usato anche in altri progetti), ho deciso di convertire un progetto Java che gestisco con un repository SVN in un repository Git.
Su questo progetto lavoro pressocché da solo, usando Eclipse e i tools SVN sviluppati dal gruppo di SVN stesso, quindi non dovrei molti problemi nella migrazione. Per sicurezza ho deciso di mantenere per alcuni giorni entrambi i progetti in Eclipse, così da poter tornare abbastanza semplicemente al sistema SVN in caso di problemi.
Di seguito i passi necessari all'installazione di EGit, il plug-in per Eclipse/Git e per l'importazione del progetto.
Installazione del plug-in per Eclipse: EGit
L'installazione del plugin non è un'operazione banale, poiché occorre importare i vari sotto progetti in Eclipse e compilarli a mano. In particolare occorre seguire i passi:
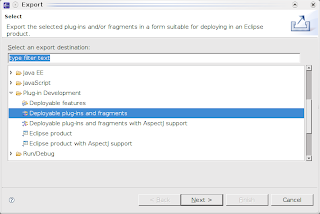
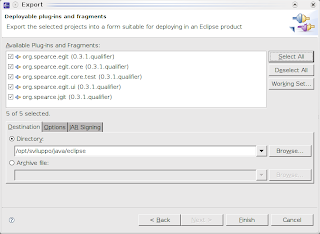
Conversione di un progetto SVN in repository Git
Nel mio caso il progetto SVN si chiama HRPM e risiede su una macchina remota. Dopo aver installato sulla mia macchina tutti i tool git, fra i quali git-svn, posso importare il progetto SVN in un repository locale git con la seguente procedura:
Avendo ora il progetto su un repository Git è possibile importare il progetto all'interno di Eclipse:
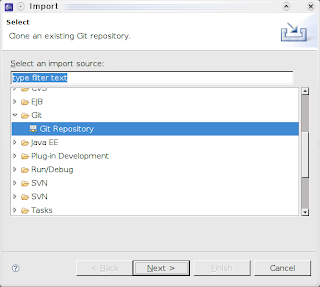
La cosa interessante è che il procedimento ha funzionato perfettamente nonostante il mio progetto fosse non un semplice progetto Java, bensì un progetto AspectJ. L'unica pecca del plug-in, almeno ad una prima vista, è l'utilizzo dei caratteri in stile CVS per indicare che il contenuto necessita di commit/aggiornamenti, mentre l'uso delle icone del plug-in SVN è sicuramente più gradevole.
Link utili:
Eclipse Git Plugin Installation
A dummy guide to use Egit
Su questo progetto lavoro pressocché da solo, usando Eclipse e i tools SVN sviluppati dal gruppo di SVN stesso, quindi non dovrei molti problemi nella migrazione. Per sicurezza ho deciso di mantenere per alcuni giorni entrambi i progetti in Eclipse, così da poter tornare abbastanza semplicemente al sistema SVN in caso di problemi.
Di seguito i passi necessari all'installazione di EGit, il plug-in per Eclipse/Git e per l'importazione del progetto.
Installazione del plug-in per Eclipse: EGit
L'installazione del plugin non è un'operazione banale, poiché occorre importare i vari sotto progetti in Eclipse e compilarli a mano. In particolare occorre seguire i passi:
- scaricare i progetti di EGit in una directory temporanea con il comando git clone git://repo.or.cz/egit.git
- importare i progetti in Eclipse. Per fare questo selezionare da Eclipse il menù File->Import->existing projects into workspace e verificare che i progetti compaiano nel project explorer.

- ora occorre compilare i progetti, per fare questo occorre darre il classi Build-All dal menù Project. Questo passo è opzionale se avete abilitato il build automatico dei progetti.
- occorre ora esportare un plug-in compatibile per Eclipse, quindi dal menù File->Export si seleziona la voce Plug-in and fragments. E' necessario impostare come percorso la root dell'installazione corrente di Eclipse.


- a questo punto è possibile riavviare Eclipse, cancellare la directory temporanea dove si sono scaricati i sorgenti di EGit, rimuovere i progetti dal project manager e verificare che il plugin sia installato. In particolare per questo è sufficiente controllare che nell'import ci sia una voce Git.
Conversione di un progetto SVN in repository Git
Nel mio caso il progetto SVN si chiama HRPM e risiede su una macchina remota. Dopo aver installato sulla mia macchina tutti i tool git, fra i quali git-svn, posso importare il progetto SVN in un repository locale git con la seguente procedura:
- creare una directory dove inserire il repository, entrare nella directory e inizializzare il repository git: git-svn init svn+ssh://host/sviluppo/svn//hrpm
- importare i sorgenti con il comando git-svn fetch -r900 (dove 900 rappresenta il numero di revisione a cui il repository SVN è arrivato)
- dopo qualche secondo (o qualche minuto), il repository git sarà pronto al suo utilizzo. E' ora possibile usare questo repository o importarlo in Eclipse.
- (opzionale) siccome il progetto importato nel repository contiene lo stesso nome del suo fratello su SVN, qualora si vogliano mantenere entrambi i progetti è necessario editare il file .project che si trova nella directory dei sorgenti cambiandone il nome, come ad esempio in HRPM-git.
Avendo ora il progetto su un repository Git è possibile importare il progetto all'interno di Eclipse:

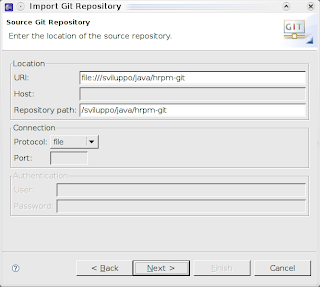
- dal menù File->Import->Git selezionare la voce Git-Repository;
- selezionare nella dialog che si apre la voce file e specificare il percorso dove risiede il repository git;

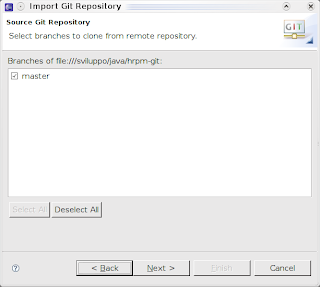
- la dialog successiva chiede quale branch si vuole importare. Siccome il repository è appena stato creato, il branch master è quello selezionato per default.

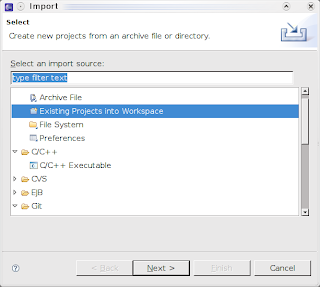
- a questo punto il progetto è importato, ma non ancora visibile in Eclipse: esiste la cartella corrispondente nel workspace, ma non il progetto nel project explorer. Per far comparire il progetto, è necessario procedere ad una successiva importazione di un progetto esistente: File->Import->Existing Project into Workspace come mostrato di seguito

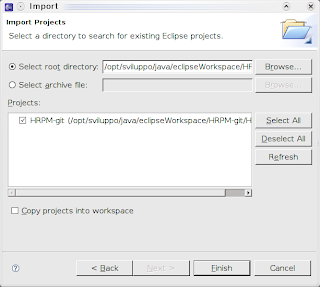
- si specifica la directory che contiene il progetto (ATTENZIONE: questa volta si deve specificare la directory all'interno del workspace) e si vedrà comparire il progetto fra quelli selezionabili. Qualora esista già un progetto con lo stesso nome Eclipse non mostrerà nessun progetto selezionabile.

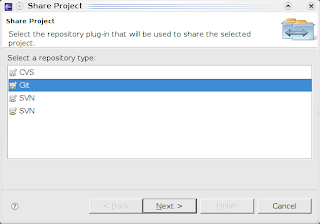
- e il progetto verrà visualizzato nel project explorer. Non è ancora finita, perché il progetto è locale, e non verrà gestito da Git. Occorre quindi fare click destro sul progetto, selezionare Team->Share Project e usare Git come metodo di condivisione.

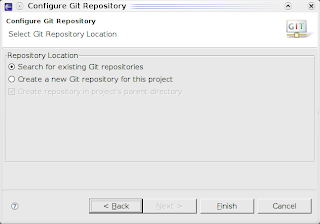
- da ultimo si informa Eclipse di usare un repository esistente, e il gioco è fatto.

La cosa interessante è che il procedimento ha funzionato perfettamente nonostante il mio progetto fosse non un semplice progetto Java, bensì un progetto AspectJ. L'unica pecca del plug-in, almeno ad una prima vista, è l'utilizzo dei caratteri in stile CVS per indicare che il contenuto necessita di commit/aggiornamenti, mentre l'uso delle icone del plug-in SVN è sicuramente più gradevole.
Link utili:
Eclipse Git Plugin Installation
A dummy guide to use Egit
martedì 18 novembre 2008
PostgreSQL Europe on-line
E' da pochi giorni disponibile il sito web del PostgreSQL Europe, il gruppo europeo per la diffusione di PostgreSQL. Fra i link amici figura anche quello di ITPUG, associazione per la promozione di PostgreSQL in Italia.
Proceedings del PGDay 2008 on-line!
Sono finalmente disponibili per il download i talk del PGDay 2008, sia in italiano che in inglese. E' possibile scaricare i talk dalla pagina del programma, semplicemente cliccando sul talk a cui si è interessati.
domenica 16 novembre 2008
Quanto farebbe Darrel oggi?
Su YouTube c'è un video di Darrel Pace in azione, e un commento abbastanza stupido al quale ho risposto e del quale discuto anche qui. Sostanzialmente ci si chiede quanto potrebbe fare Darrel Pace oggi con gli equipaggiamenti tecnologici che sono presenti sui campi di gara, e la risposta che è stata data è che gli equipaggiamente di oggi non sono significativamente migliori di quelli di venti anni fa! Non sono per niente d'accordo con una simile affermazione. Se è infatti vero che venti anni fa i punti si facevano anche con attrezzature non paragonabili a quelle attuali, l'equipaggiamento di oggi è sicuramente migliore di quello che c'era allora. Ricordo che Ferrari e Spigarelli passavano abbondantemente i 1300 anche con frecce in alluminio, e lo stesso Pace vinse l'olimpiade di L.A. 1984 con frecce in alluminio dando circa 50 punti al secondo (McKinney). E se è vero che Pace aveva un record del mondo di 1340 punti, in che condizioni doveva essere per poter fare tali punteggi? Intendo dire che gli equipaggiamenti di adesso consentono di sopperire a molti problemi climatico-fisici del contesto di gara. Ad esempio flettenti e frecce veloci consentono di compensare problemi di vento in modo più semplice. Quindi è vero che un atleta capace di fare 1300 punti con frecce di alluminio farà punteggi analoghi con frecce al carbonio, ma sicuramente li farà in modo più costante. E una volta trovata la messa a punto ideale allora farà ancora di più. Altrimenti non si spiegherebbe come mai si sia dovuto attendere gli anni 2000 per avere il primo 1400 femminile.
Infine ritengo che il materiale faccia la differenza per tutti gli arcieri mediocri o bravini, che grazie a tecnologie migliori possono compensare le loro mancanze tecniche o psico-fisiche. A titolo di esempio riporto la mia esperienza con i doinker: montati qualche mese fa hanno subito smorzato le vibrazioni in eccesso del mio arco. Ora, ricordo bene, che i grandi campioni tiravano con archi silenziosissimi anche senza doinker. Cosa significa questo? Che loro erano in grado di far funzionare il materiale meglio, mentre io, comune mortale, devo compensare alla mia incapacità tecnica (o alla mia impreparazione) con del materiale tecnologicamente migliore.
Infine ritengo che il materiale faccia la differenza per tutti gli arcieri mediocri o bravini, che grazie a tecnologie migliori possono compensare le loro mancanze tecniche o psico-fisiche. A titolo di esempio riporto la mia esperienza con i doinker: montati qualche mese fa hanno subito smorzato le vibrazioni in eccesso del mio arco. Ora, ricordo bene, che i grandi campioni tiravano con archi silenziosissimi anche senza doinker. Cosa significa questo? Che loro erano in grado di far funzionare il materiale meglio, mentre io, comune mortale, devo compensare alla mia incapacità tecnica (o alla mia impreparazione) con del materiale tecnologicamente migliore.
venerdì 14 novembre 2008
Compilazione incrementale Ant usando AspectJ in Eclipse
Dopo aver aggiornato i tools di sviluppo di AspectJ per Ecplise (AJDT) alla versione 1.6.1, mi sono trovato una brutta sorpresa nella compilazione tramite Ant (task iajc): la compilazione incrementale non funziona più se non si specifica un parametro sourceRoots che è praticamente equivalente al precedente parametro che indica la directory che contiene i sorgenti. Ma ahimé nemmeno così la compilazione incrementale può funzionare, e infatti si ottiene la schermata di Eclipse che segue:

Il fatto è che Ant non può sapere quali file sono stati modificati, e quindi quali sorgenti debbano essere applicati dal weaver, percui di fatto ant rimane in attesa come processo attendendo di ricompilare nuovamente il set dei sorgenti. Quindi il task iacj diventa una sorta di processo che non termina mai e che addende sempre input dall'utente per ricompilare. Non esiste quindi nessuna soluzione apparente per usare ant in incremental mode all'interno di Eclipse, percui ci si deve rivolgere al compilare degli AJDT per avere una compilazione incrementale.

Il fatto è che Ant non può sapere quali file sono stati modificati, e quindi quali sorgenti debbano essere applicati dal weaver, percui di fatto ant rimane in attesa come processo attendendo di ricompilare nuovamente il set dei sorgenti. Quindi il task iacj diventa una sorta di processo che non termina mai e che addende sempre input dall'utente per ricompilare. Non esiste quindi nessuna soluzione apparente per usare ant in incremental mode all'interno di Eclipse, percui ci si deve rivolgere al compilare degli AJDT per avere una compilazione incrementale.
Visualizzazione delle variabili GUC
Le variabili GUC (Global User Configuration) possono essere visualizzate in un terminale SQL con il comando SHOW, specificando esattamente il nome della variabile (es. SHOW add_missing_from) oppure con l'opzione ALL che mostrerà una tabella contenente il nome della variabile, la sua descrizione e il suo valore attuale.
Aggiornamento a Kubuntu Intrepid
Ho aggiornato il mio laptop alla nuova versione di Kubuntu, Intrepid (8.10). Il nuovo KDE è veramente molto bello, anche se ci sono diverse cose ancora da sistemare (per esempio l'altezza del pannello che non sembra essere regolabile).
Ahimé all'avvio del nuovo sistema tutte le mie impostazioni (posta, im, ecc.) erano perse! Il problema è che, non essendo più supportato KDE 3 in Kubuntu, la directory di installazione ~/.kde4 non ha più senso di esistere, e quindi le impostazioni sono state copiate nuovamente in ~/.kde. Basta copiare i file di configurazione nella directory ~/.kde per riavere le proprie impostazioni.
Ci sono stati anche alcuni problemi con dei programmi, ma è stato sufficiente reinstallarli per fissare il problema.
Ahimé all'avvio del nuovo sistema tutte le mie impostazioni (posta, im, ecc.) erano perse! Il problema è che, non essendo più supportato KDE 3 in Kubuntu, la directory di installazione ~/.kde4 non ha più senso di esistere, e quindi le impostazioni sono state copiate nuovamente in ~/.kde. Basta copiare i file di configurazione nella directory ~/.kde per riavere le proprie impostazioni.
Ci sono stati anche alcuni problemi con dei programmi, ma è stato sufficiente reinstallarli per fissare il problema.
lunedì 10 novembre 2008
Questione di igiene
Evidentemente l'igiene non è più una cosa così importante, eppure i miei genitori mi hanno sempre educato a non toccare tutto quello che vedo, a lavarmi le mani prima di mangiare, ma....
...a cena in un ristorante ho dovuto far portare indietro il mio bicchiere di birra perché puzzava di benzina! Evidentemente chi ha spillato la birra aveva appena fatto il pieno all'auto senza lavarsi le mani (e non oso pensare a questo punto il cibo come era stato trattato).
...in una farmacia dove ho fatto una visita il computer collegato agli elettrodi aveva un dito di polvere, tanto che l'operatrice lavorandoci lasciava le impronte sul case.
...ad una mostra canina a cui ho partecipato un sacco di bambini giocavano per terra, mettendosi in bocca dita e altri oggetti. Peccato che per terra i cani facessero anche i loro bisogni.
Sarò paranoico, ma forse un po' di igiene e pulizia non guasterebbe, almeno nelle situazioni più lampanti!
...a cena in un ristorante ho dovuto far portare indietro il mio bicchiere di birra perché puzzava di benzina! Evidentemente chi ha spillato la birra aveva appena fatto il pieno all'auto senza lavarsi le mani (e non oso pensare a questo punto il cibo come era stato trattato).
...in una farmacia dove ho fatto una visita il computer collegato agli elettrodi aveva un dito di polvere, tanto che l'operatrice lavorandoci lasciava le impronte sul case.
...ad una mostra canina a cui ho partecipato un sacco di bambini giocavano per terra, mettendosi in bocca dita e altri oggetti. Peccato che per terra i cani facessero anche i loro bisogni.
Sarò paranoico, ma forse un po' di igiene e pulizia non guasterebbe, almeno nelle situazioni più lampanti!
giovedì 6 novembre 2008
Compilare PostgreSQL in Eclipse 3.4
Eclipse può essere usato come ambiente di sviluppo/compilazione/studio di PostgreSQL, basta avere i CDT installati (C Development Tools).
Di seguito i passi per configurare Eclipse per il build di PostgreSQL.
Di seguito i passi per configurare Eclipse per il build di PostgreSQL.
- Scaricare i sorgenti di PostgreSQL, decomprimerli in una directory (es /sviluppo/src/postgresql-8.3.5).
- Configurare i sorgenti per un build tramite make, quindi dalla directory principale del pacchetto scaricare lanciare il comando configure come ad esempio in:
./configure --prefix=/sviluppo/sr/postgresqlbin --enable-depend --enable-cassert --enable-debug





- avviare Eclipse e creare un nuovo progetto, di tipo C, Makefile e vuoto.

- dare un nome simbolico al progetto (es. PostgreSQL) e, una volta creato il progetto, fare click destro su di esso e selezionare la voce import. Dalla finestra di dialogo che appare selezionare la directory radice risultante dalla scompattazione del pacchetto scaricato.


- L'importazione dei file produrrà una struttura del progetto simile a quella in figura.

- Una volta terminata l'importazione dei sorgenti, è possibile lanciare un build dell'ambiente e vedere la compilazione in corso attraverso la console di Eclipse.

smbldap e scadenza password
Per default quando si utilizzano i smbldap-tools per l'autenticazione Samba/Unix unificata tramite Samba viene abilitato un tempo di scadenza password di 45 giorni. E' possibile rimuovere la gestione della scadenza password, o impostare un intervallo di tempo differente, agendo sul parametro defaultMaxPasswordAge del file /etc/smbldap-tools/smbldap.conf.
Quanta fretta
Non posso fare a meno di notare come la gente sembri avere una gran fretta, o meglio una grande maleducazione mascherata da fretta.
Solo per citare alcuni episodi che mi sono capitati:
Solo per citare alcuni episodi che mi sono capitati:
- una persona in fila davanti a me alla cassa della coop era così impegnata a telefonare che non ascoltava la cassiera e si è anche dimenticato il resto
- una persona in palestra ha smesso di fare esercizi per rispondere ad un messaggio al cellulare
- una mamma mi ha impedito di uscire da un parcheggio perché aveva messo la sua macchina davanti alla mia, a circa 10 mt. dall'ingresso della scuola (non si sa mai che si ammali camminando troppo). Quando finalmente sono riuscito a rintracciarla e a farle spostare la macchina, mi ha comunque ostacolato nella manovra di uscita e si è ripiazzata in modo assurdo appena me ne sono andato.
- davanti a casa ho una rientranza nel marciapiede fatta apposta per far sostare una macchina, ma tipicamente tutti vi parcheggiano senza far manovra, lasciando quindi la macchina in mezzo alla strada.
martedì 4 novembre 2008
Acrobat Reader: stampare i commenti
Mi è capitato di dover stampare un documento PDF contenente dei commenti, che nella visualizzazione compaiono come popup, ma che in stampa vengono solo marcati come segnalini privi di contenuto. Dopo un po' di esperimenti ho capito che con Okular non avevo modo di stampare i commenti, così da un computer Windows ho provato con Acrobat Reader...ma niente! Il risultato era sempre lo stesso. E parlo di Acrobat Reader 9, non un reader datato. Ebbene ho trovato che modificando la chiave di registro HKEY_CURRENT_USER\Software\ADOBE\Acrobat Reader\9.0\Annots\cPrefs\bprintCommentPopups da 0 a 1 il programma stampa i popup con le note. Certo non è una stampa molto pulita, poiché i popup vengono stampati in posizioni "random" sopra al testo, ma è meglio di niente.
Sicuramente l'Adobe potrebbe migliorare le opzioni del suo diffusissimo Reader per supportare meglio i commenti. Anche un'opzione per stampare i commenti nell'ultima pagina, un po' come fossero delle note numerate.
Sicuramente l'Adobe potrebbe migliorare le opzioni del suo diffusissimo Reader per supportare meglio i commenti. Anche un'opzione per stampare i commenti nell'ultima pagina, un po' come fossero delle note numerate.
Mappare le singole proprietà degli oggetti su un database
In questi giorni sto lavorando ad una applicazione PHP che mappa degli oggetti su dei dati che risiedono su un database relazionale. Nulla di nuovo, nulla di sconvolgente, si tratta di un normale mapping ORM. Il problema è che l'applicazione è lenta, anzi lentissima, per quelle che sono le capacità del server e della rete su cui gira.
Il primo passo per me è stato analizzare i log di PostgreSQL (il database server che ospita i dati) per cercare di capire che tipo di query venivano lanciate. Ebbene ho trovato una serie di micro-query ripetute in modo massivo, e analizzando il codice ho trovato che ogni singolo dato di un oggetto veniva sempre riletto dal database ogni volta che veniva acceduto. In sostanza quindi ogni operazione di get forzava un reload del singolo dato dal database, e quindi il traffico di query, tutte piccole e poco ottimizate (e ottimizzabili) diventava enorme. La mappatura ORM prevede quindi di non tenere in memoria le proprietà di un oggetto ma di ricaricarle ogni volta che queste vengano richieste direttamente dal database. E' evidente che in quest'ottica i singoli metodi get non possono essere ottimizzati, ma si può procedere ad una velocizzazione delle operazioni per metodi getAll su più proprietà dello stesso oggetto. In sostanza si tratta di creare metodi wrapper attorno a più operazioni di get, facendo eseguire però una singola operazione sul database. Se ad esempio si hanno i metodi getNome e getCognome, considerando che nell'applicazione molto spesso occorrono entrambi i dati, si può costruire una funzione getNomeCognome che restituisca un array con entrambi i dati. Al suo interno la funzione non farà affidamento sui due servizi getNome e getCognome, perché questo significherebbe creare due query sul database, bensì effettuerà una query unica verso il database. Sfruttando quindi questi metodi get-combinati si possono ottenere tutti i dati che servono al flusso dell'applicazione con query uniche e quindi riducendo il traffico di rete e la latenza del database.
Il primo passo per me è stato analizzare i log di PostgreSQL (il database server che ospita i dati) per cercare di capire che tipo di query venivano lanciate. Ebbene ho trovato una serie di micro-query ripetute in modo massivo, e analizzando il codice ho trovato che ogni singolo dato di un oggetto veniva sempre riletto dal database ogni volta che veniva acceduto. In sostanza quindi ogni operazione di get forzava un reload del singolo dato dal database, e quindi il traffico di query, tutte piccole e poco ottimizate (e ottimizzabili) diventava enorme. La mappatura ORM prevede quindi di non tenere in memoria le proprietà di un oggetto ma di ricaricarle ogni volta che queste vengano richieste direttamente dal database. E' evidente che in quest'ottica i singoli metodi get non possono essere ottimizzati, ma si può procedere ad una velocizzazione delle operazioni per metodi getAll su più proprietà dello stesso oggetto. In sostanza si tratta di creare metodi wrapper attorno a più operazioni di get, facendo eseguire però una singola operazione sul database. Se ad esempio si hanno i metodi getNome e getCognome, considerando che nell'applicazione molto spesso occorrono entrambi i dati, si può costruire una funzione getNomeCognome che restituisca un array con entrambi i dati. Al suo interno la funzione non farà affidamento sui due servizi getNome e getCognome, perché questo significherebbe creare due query sul database, bensì effettuerà una query unica verso il database. Sfruttando quindi questi metodi get-combinati si possono ottenere tutti i dati che servono al flusso dell'applicazione con query uniche e quindi riducendo il traffico di rete e la latenza del database.
Gara indoor di Modena
Domenica scorsa si è tenuta a Modena la gara indoor dell'Aquila Bianca, e così al pomeriggio sono andato con la mia ragazza a fare un giro per vedere un po' come si svolgono le competizioni adesso (sono circa 8 anni che non partecipo ad una gara).
E' stato molto emozionante, anche perché ho rivisto un sacco di persone di cui avevo perso notizie. Ho speso buona parte del tempo a fare pubbliche relazioni più che a guardare gli atleti tirare, e mi ha fatto molto piacere che tutti mi abbiano incitato a tornare sui campi di gara (anche se ritengo sia ancora presto). Mi ha chiaramente fatto anche molto piacere vedere il mio primo allenatore e la sua famiglia, nonché ritrovare tanti vecchi compagni di allenamenti.
Non ho poi potuto fare a meno di notare come, oggi, i più giovani siano già dotati di equipaggiamento all'ultimo grido, e non parlo di tecnologia, quanto di moda. Sono rimasto infatto sorpreso di vedere quante faretre della Angel vi erano sulla linea di tiro, e quante di queste erano portate da ragazzi. Ora, essendo io cresciuto con la scuola del "quel che non c'è non si rompe", ho sempre dedicato più attenzione ai materiali (sempre di primissimo ordine, grazie ai sacrifici dei miei genitori) che non alla moda. Inoltre, ricordo che all'epoca l'unico atleta che conoscevo e che aveva una faretra della Angel era Andrea, l'unico degno di portare un simile oggetto. E nonostante dica tutto questo, anche io alla fine ho ordinato una simile faretra, ma mentre io l'ho ordinata dopo anni di tiro, valutando attentamente la spesa e dicendo esplicitamente che non merito una simile faretra (e lo penso realmente), non mi capacito di questa diffusione alla moda fra i più giovani. Sicuramente è una para mentale, se si pensa che è solo una faretra, ma forse è anche questo un indice di come i giovani stiano perdendo il valore degli oggetti e dei sacrifici per averli.
E' stato molto emozionante, anche perché ho rivisto un sacco di persone di cui avevo perso notizie. Ho speso buona parte del tempo a fare pubbliche relazioni più che a guardare gli atleti tirare, e mi ha fatto molto piacere che tutti mi abbiano incitato a tornare sui campi di gara (anche se ritengo sia ancora presto). Mi ha chiaramente fatto anche molto piacere vedere il mio primo allenatore e la sua famiglia, nonché ritrovare tanti vecchi compagni di allenamenti.
Non ho poi potuto fare a meno di notare come, oggi, i più giovani siano già dotati di equipaggiamento all'ultimo grido, e non parlo di tecnologia, quanto di moda. Sono rimasto infatto sorpreso di vedere quante faretre della Angel vi erano sulla linea di tiro, e quante di queste erano portate da ragazzi. Ora, essendo io cresciuto con la scuola del "quel che non c'è non si rompe", ho sempre dedicato più attenzione ai materiali (sempre di primissimo ordine, grazie ai sacrifici dei miei genitori) che non alla moda. Inoltre, ricordo che all'epoca l'unico atleta che conoscevo e che aveva una faretra della Angel era Andrea, l'unico degno di portare un simile oggetto. E nonostante dica tutto questo, anche io alla fine ho ordinato una simile faretra, ma mentre io l'ho ordinata dopo anni di tiro, valutando attentamente la spesa e dicendo esplicitamente che non merito una simile faretra (e lo penso realmente), non mi capacito di questa diffusione alla moda fra i più giovani. Sicuramente è una para mentale, se si pensa che è solo una faretra, ma forse è anche questo un indice di come i giovani stiano perdendo il valore degli oggetti e dei sacrifici per averli.
giovedì 30 ottobre 2008
Importazioni immagini in PostgreSQL: un semplice script shell
Qualche giorno fa mi sono trovato a dover inserire una serie di immagini di persone in un database aziendale, ovviamente facendo corrispondere ciascuna persona alla propria immagine. Siccome il software che sto sviluppando non permette (ancora) di associare ad una persona la propria immagine, mentre consente di visualizzarla, ho deciso di caricare le immagini da linea di comando. Il problema era come mappare ogni immagine con la relativa persona. Purtroppo le immagini erano tutte nominate nella forma nome_cognome, e quindi l'unica strada era quella di sfruttare i relativi dati nel database. Ovviamente questo rischia di creare problemi in casi di omonimia, ma dopotutto è più rapido correggere alcune immagini sbagliate che inserirle una per una a mano!
Ho quindi creato il seguente script shell che fa il lavoro sporco:
Come si può notare prima faccio un po' di pulizia sul nome del file (le immagini erano tutte .tif) e ottengo la stringa nome_cognome, e procedo ad una conversione nel formato richiesto dalla mia applicazione (png). Successivamente estraggo i singoli pezzi (nome e cognome) e costruisco una stringa di comando SQL per l'update di un campo blob (image) della tabella corrispondente (person). La query SQL effettua un update dove trova corrispondenza di nome e cognome o dove trova anche solo il cognome (a patto che ve ne sia solo uno). Tutte le query SQL vengono salvate in un file che viene poi lanciato da un terminale psql. Da notare che tutti gli inserimenti avvengono all'interno di una transazione, per evitare problemi di incoerenza (o si caricano tutte le immagini o nessuna).
Ho quindi creato il seguente script shell che fa il lavoro sporco:
#!/bin/bash
SQL_FILE="immagini.sql"
echo "BEGIN;" > $SQL_FILE
for img in *.tif
do
echo "\t==== Processo immagine $img ==="
NAME=`basename $img .tif`
NAME=`echo $NAME | sed 's/_N//;'`
NAME=`echo $NAME | sed 's/_B//;'`
NAME=`echo $NAME | sed 's/_[1-9]//;'`
NAME=`echo $NAME | tr [:upper:] [:lower:]`
echo "=> $NAME"
FILE_PNG=$NAME.png
FILE_PNG_1=$NAME_1.png
# conversione immagine
if [ ! -f $FILE_PNG ]
then
convert $img -quality 100 $FILE_PNG_1
convert $FILE_PNG_1 -resize 30% $FILE_PNG
fi
# estraggo nome e cognome
sql_surname=`echo $NAME | awk -F_ '{print $1;}'`
if [ -z "$sql_surname" ]
then
sql_surname="XXX"
fi
sql_name=`echo $NAME | awk -F_ '{print $2;}'`
if [ -z "$sql_name" ]
then
sql_name="YYY"
fi
CURRENT_DIR=`pwd`
echo -en "UPDATE person SET image = lo_import('$CURRENT_DIR/$FILE_PNG') WHERE " >> $SQL_FILE
echo -en " (lower(name)='$sql_name' AND lower(surname)='$sql_surname') " >> $SQL_FILE
echo -en " OR " >> $SQL_FILE
echo -en " (lower(surname)='$sql_surname' AND (SELECT COUNT(surname) FROM person WHERE lower(surname)='$sql_surname') = 1 )" >> $SQL_FILE
echo ";" >> $SQL_FILE
done
echo -en "\n\nCOMMIT;\n" >> $SQL_FILE
Come si può notare prima faccio un po' di pulizia sul nome del file (le immagini erano tutte .tif) e ottengo la stringa nome_cognome, e procedo ad una conversione nel formato richiesto dalla mia applicazione (png). Successivamente estraggo i singoli pezzi (nome e cognome) e costruisco una stringa di comando SQL per l'update di un campo blob (image) della tabella corrispondente (person). La query SQL effettua un update dove trova corrispondenza di nome e cognome o dove trova anche solo il cognome (a patto che ve ne sia solo uno). Tutte le query SQL vengono salvate in un file che viene poi lanciato da un terminale psql. Da notare che tutti gli inserimenti avvengono all'interno di una transazione, per evitare problemi di incoerenza (o si caricano tutte le immagini o nessuna).
mercoledì 29 ottobre 2008
Explain su tabella vuote
Mi sono accorto per caso, preparando le slide del LinuxDay 2008, che l'EXPLAIN di PostgreSQL si comporta in modo strano quando la tabella è vuota.
Ad esempio:
quindi la tabella è vuota, e anche se ci si esegue un ANALYZE su di essa, l'ottimizzatore continua a sostenere che 880 righe possono essere ottenute da essa. Mi sono poi accorto che nel caso di tabella vuota non viene inserita nessuna statistica in pg_stats, e quindi l'ottimizzatore non ha modo di capire che la tabella sia vuota (o meglio potrebbe capirlo solo dal fatto che non esiste una statistica in pg_stats, ma questo può anche ricondurre ad un caso di tabella non analizzata). L'ottimizzatore tenta quindi di fare una stima delle tuple che potrebbe essere contenute nella tabella, dipendentemente dalla dimensione della pagina dati e dalla dimensione della tupla stessa.
Ad esempio:
# create table test(id serial, descrizione character varying(20));
# explain select * from test;
QUERY PLAN
--------------------------------------------------------
Seq Scan on test (cost=0.00..18.80 rows=880 width=62)
# analyze verbose test;
INFO: analyzing "public.test"
INFO: "test": scanned 0 of 0 pages, containing 0 live rows and 0 dead rows; 0
rows in sample, 0 estimated total rows
ANALYZE
# explain select * from test;
QUERY PLAN
--------------------------------------------------------
Seq Scan on test ?(cost=0.00..18.80 rows=880 width=62)
(1 row)
# select count(*) from test;
count
-------
0
(1 row)
quindi la tabella è vuota, e anche se ci si esegue un ANALYZE su di essa, l'ottimizzatore continua a sostenere che 880 righe possono essere ottenute da essa. Mi sono poi accorto che nel caso di tabella vuota non viene inserita nessuna statistica in pg_stats, e quindi l'ottimizzatore non ha modo di capire che la tabella sia vuota (o meglio potrebbe capirlo solo dal fatto che non esiste una statistica in pg_stats, ma questo può anche ricondurre ad un caso di tabella non analizzata). L'ottimizzatore tenta quindi di fare una stima delle tuple che potrebbe essere contenute nella tabella, dipendentemente dalla dimensione della pagina dati e dalla dimensione della tupla stessa.
Disabilitare quell'odioso beep delle console dei server....
Quando mi trovo a lavorare direttamente sulla console di un server più volte vengono rimproverato dal beep della console stessa, che arriva quasi ad infastidirmi. E' possibile disabilitare il suono del terminale con il comando:
setterm -blength 0
e le orecchie si riposano!
martedì 28 ottobre 2008
lunedì 27 ottobre 2008
PostgreSQL @ LinuxDay 2008
Sabato si è svolto il LinuxDay, e io ho avuto l'opportunità di partecipare all'edizione di Modena presentando PostgreSQL e ITPug. Anzitutto mi complimento con i ragazzi di Conoscere Linux per l'ottima organizzazione dell'evento, e ringrazio il loro presidente, Giordano Lanzi, per avermi dato l'opportunità di partecipare nonostante lo scarso preavviso. Ringrazio anche il mio amico Luca "Marty" per avermi prestato il suo portatile per la presentazione, visto che il mio soffre di qualche problema all'uscita video.
Il talk ha avuto una buona partecipazione e un buon interesse, diciamo che sono riuscito a dare una buona visione del perché PostgreSQL è un database di classe enterprise. Il talk è iniziato con un po' di storia del progetto e qualche parola sulla community PostgreSQL e ITPug, dopodiché è passato all'installazione e uso basilare del sistema, per poi passare ad alcuni meccanismi interni (layout su disco, cataloghi, statistiche, WAL, PITR, MVCC, lock).
Il talk ha avuto una buona partecipazione e un buon interesse, diciamo che sono riuscito a dare una buona visione del perché PostgreSQL è un database di classe enterprise. Il talk è iniziato con un po' di storia del progetto e qualche parola sulla community PostgreSQL e ITPug, dopodiché è passato all'installazione e uso basilare del sistema, per poi passare ad alcuni meccanismi interni (layout su disco, cataloghi, statistiche, WAL, PITR, MVCC, lock).
.pgpass e nomi host in pg_dump
Ho scoperto quasi per caso che l'utility pg_dump quando usa il file .pgpass per l'accesso trasparente ad un database non tiene in considerazione di eventuali nomi host o alias. In altre parole, se all'interno del file .pgpass l'host viene specificato con un indirizzo IP, nella riga di comando pg_dump non si può specificare il nome host, poiché il file .pgpass viene testato con una comparazione secca sul testo che compare nella posizione dell'host e il testo passato sulla riga di comando.
sabato 18 ottobre 2008
PGDay 2008: giorno 2
Anche la seconda giornata del PGDay 2008 si è rivelata un successo. Alla fine della manifestazione tutti i partecipanti si sono congratulati con gli organizzatori per l'ottimo livello dei talk e dei servizi messi a disposizione. Giusto per dare qualche numero, si calcola che i visitatori totali siano stati 171!!!!!
L'assemblea ITPug è stata seguita con attenzione e interesse anche dai non soci, e molte persone si sono dette interessate ad iscriversi quanto prima. E' parso evidente l'interesse comune nel promuovere PostgreSQL in Italia, e tutti vogliono poter fare il loro pezzetto per far guadagnare a PostgreSQL punti in più.
Sono stato fermato parecchie volte da gente che continuava a chiedermi informazioni su Java, sul driver JDBC e con alcuni di loro ho anche potuto lanciarmi in riflessioni filosofiche su PostgreSQL stesso.
Sono soddisfatto dei talk e dei corsi che ho seguito, l'ultimo dei quali, Partitioning di Enrico, ha scatenato una interessantissima discussione.
Sono contento di aver avuto l'opportunità di far nuovamente parte di un evento così grande, e sono contento che i soci di ITPug e gli altri volontari abbiano avuto fiducia nella realizzazione del PGDay e si siano impegnati per farlo riuscire al meglio (e meglio di così penso fosse realmente difficile!) nonostante qualche preoccupazione espressa in passato. E a tutti i volontari va un grossissimo ringraziamento per i loro sforzi.
Sono inoltre molto contento che i ragazzi di psql.it abbiano partecipato attivamente alla conferenza, mostrando un sincero interesse per il lavoro svolto da ITPug in questo suo primo anno di vita.
Ho ritrovato in questi giorni la cordialità, la curiosità e la voglia di collaborazione che sembra caratterizzare tutti gli utenti di PostgreSQL.
Un'esperienza veramente appagante.
L'assemblea ITPug è stata seguita con attenzione e interesse anche dai non soci, e molte persone si sono dette interessate ad iscriversi quanto prima. E' parso evidente l'interesse comune nel promuovere PostgreSQL in Italia, e tutti vogliono poter fare il loro pezzetto per far guadagnare a PostgreSQL punti in più.
Sono stato fermato parecchie volte da gente che continuava a chiedermi informazioni su Java, sul driver JDBC e con alcuni di loro ho anche potuto lanciarmi in riflessioni filosofiche su PostgreSQL stesso.
Sono soddisfatto dei talk e dei corsi che ho seguito, l'ultimo dei quali, Partitioning di Enrico, ha scatenato una interessantissima discussione.
Sono contento di aver avuto l'opportunità di far nuovamente parte di un evento così grande, e sono contento che i soci di ITPug e gli altri volontari abbiano avuto fiducia nella realizzazione del PGDay e si siano impegnati per farlo riuscire al meglio (e meglio di così penso fosse realmente difficile!) nonostante qualche preoccupazione espressa in passato. E a tutti i volontari va un grossissimo ringraziamento per i loro sforzi.
Sono inoltre molto contento che i ragazzi di psql.it abbiano partecipato attivamente alla conferenza, mostrando un sincero interesse per il lavoro svolto da ITPug in questo suo primo anno di vita.
Ho ritrovato in questi giorni la cordialità, la curiosità e la voglia di collaborazione che sembra caratterizzare tutti gli utenti di PostgreSQL.
Un'esperienza veramente appagante.
venerdì 17 ottobre 2008
PGDay 2008: giorno 1
Ci siamo, il PGDay 2008 è in corso, oggi si è svolto presso la bellissima sede della Monash University di Prato il primo giorno della conferenza.
Sono rimasto piacevolmeten soddisfatto dall'affluenza, maggiore dell'anno scorso, e dall'interesse crescente per PostgreSQL e per l'associazione ITPug.
Questa prima giornata è stata un'ottima occasione per rivedere gli amici e colleghi di ITPug, nonché amici e colleghi volontari di altre associazioni e comunità. Nella mattina si è svolto il keynote di Dave e Magnus, seguito poi dall'inizio dei talk. La sessione italiana si è aperta con un talk molto interessante sulla gestione di informazioni spaziali di cartelli e insegne, proseguendo poi con altri validi talk relativi al mondo GIS. Non ho potuto purtroppo seguire tutti i talk perché a fine mattina ho tenuto, assieme ad Enrico, la prima parte del corso di connettività PostgreSQL da diversi linguaggi. A me chiaramente è toccata la parte Java, e devo dire che ho visto un interesse maggiore rispetto all'anno scorso, forse anche per la drastica riduzione dei lucidi e degli argomenti trattati, nonché per una sostanziale semplificazione degli esempi che hanno probabilmente reso il corso più comprensibile. La parte del corso Java è terminata nel primo pomeriggio, dopo la foto di gruppo e un ottimo pranzo gustato sulla terrazza della sala Veneziana assieme agli amici volontari del PGDay. Il pomeriggio poi è passato veloce seguendo un altro corso sulla migrazione da MySQL a PostgreSQL (tenuto da Gabriele) e la presentazione al pubblico di ITPug.
L'aperitivo offerto da EnterpriseDB e la pizza con gli amici (vecchi e nuovi) ha concluso la prima giornata della conferenza.
Sono molto contento che la conferenza stia procedendo così bene, anche se un po' si sente la mancanza di alcuni nomi illustri dell'anno scorso...non che i nomi importanti manchino, anzi! E poi quest'anno con la developer room permanente il livello tecnico e il numero di sviluppatori è veramente alto.
Sono rimasto piacevolmeten soddisfatto dall'affluenza, maggiore dell'anno scorso, e dall'interesse crescente per PostgreSQL e per l'associazione ITPug.
Questa prima giornata è stata un'ottima occasione per rivedere gli amici e colleghi di ITPug, nonché amici e colleghi volontari di altre associazioni e comunità. Nella mattina si è svolto il keynote di Dave e Magnus, seguito poi dall'inizio dei talk. La sessione italiana si è aperta con un talk molto interessante sulla gestione di informazioni spaziali di cartelli e insegne, proseguendo poi con altri validi talk relativi al mondo GIS. Non ho potuto purtroppo seguire tutti i talk perché a fine mattina ho tenuto, assieme ad Enrico, la prima parte del corso di connettività PostgreSQL da diversi linguaggi. A me chiaramente è toccata la parte Java, e devo dire che ho visto un interesse maggiore rispetto all'anno scorso, forse anche per la drastica riduzione dei lucidi e degli argomenti trattati, nonché per una sostanziale semplificazione degli esempi che hanno probabilmente reso il corso più comprensibile. La parte del corso Java è terminata nel primo pomeriggio, dopo la foto di gruppo e un ottimo pranzo gustato sulla terrazza della sala Veneziana assieme agli amici volontari del PGDay. Il pomeriggio poi è passato veloce seguendo un altro corso sulla migrazione da MySQL a PostgreSQL (tenuto da Gabriele) e la presentazione al pubblico di ITPug.
L'aperitivo offerto da EnterpriseDB e la pizza con gli amici (vecchi e nuovi) ha concluso la prima giornata della conferenza.
Sono molto contento che la conferenza stia procedendo così bene, anche se un po' si sente la mancanza di alcuni nomi illustri dell'anno scorso...non che i nomi importanti manchino, anzi! E poi quest'anno con la developer room permanente il livello tecnico e il numero di sviluppatori è veramente alto.
mercoledì 15 ottobre 2008
Caricare immagini da un database
Il seguente metodo legge una immagine memorizzata come BLOB in un database PostgreSQL (tipo di dato OID) e la converte in un'immagine Java.
L'idea è quella di avere una classe Person che memorizza le informazioni di una persona, fra le quali la propria immagine. La classe mantiene una variabile image che funge da cache per l'immagine della persona: se l'immagine è già stata caricata essa non viene riletta dal database per motivi di efficienza.
Il metodo getImage() carica l'immagine dal database. Al di là delle operazioni preliminari, specifiche di un framework e comunque riconducibili facilmente a JDBC, il metodo ottiene il ResultSet relativo all'immagine, e da questo preleva il BLOB dell'immagine. Tale blob viene poi usato per ottenere lo stream di input dell'immagine. Tale stream viene passato alla classe ImageIO, utilizzata appunto per caricare una immagine da uno stream di byte.
L'idea è quella di avere una classe Person che memorizza le informazioni di una persona, fra le quali la propria immagine. La classe mantiene una variabile image che funge da cache per l'immagine della persona: se l'immagine è già stata caricata essa non viene riletta dal database per motivi di efficienza.
Il metodo getImage() carica l'immagine dal database. Al di là delle operazioni preliminari, specifiche di un framework e comunque riconducibili facilmente a JDBC, il metodo ottiene il ResultSet relativo all'immagine, e da questo preleva il BLOB dell'immagine. Tale blob viene poi usato per ottenere lo stream di input dell'immagine. Tale stream viene passato alla classe ImageIO, utilizzata appunto per caricare una immagine da uno stream di byte.
/**
* The image of this person.
*/
private Image image = null;
/**
* Returns the image of this person.
* @return the image of the person
*/
public synchronized Image getImage(){
// do I have already loaded an image?
if( this.image != null )
return this.image;
// if here the image is not yet loaded, so load it from the database
try{
Logger.debug("Start loading the image of the person " + this.personPK);
String sql = "SELECT image FROM person WHERE personpk=? AND image IS NOT NULL";
Object params[] = {this.personPK};
Database database = Database.getInstance();
database.initTransaction();
ResultSet rs = database.query(sql, params);
while( rs != null && rs.next() ){
Blob imageBlob = rs.getBlob("image");
long size = imageBlob.length();
byte[] imageBytes = imageBlob.getBytes(1, (int) size);
Logger.debug("the image has size in bytes: " + size);
this.image = ImageIO.read( new ByteArrayInputStream(imageBytes));
}
// all done
Logger.debug("end loading image");
database.commit();
return this.image;
}catch(DatabaseException e){
Logger.exception("Exception caught while loading a person's image", e);
return null;
} catch (SQLException e) {
Logger.exception("Exception caught while loading a person's image", e);
return null;
} catch (IOException e) {
Logger.exception("Exception caught while loading a person's image", e);
return null;
}
}
lunedì 13 ottobre 2008
Un matrimonio da record
I due arcieri coreani Park e Park si sposeranno questo Dicembre. Visto che sono due fra i più forti arcieri al mondo (o meglio, lei è sicuramente la più forte al mondo) e che entrambi hanno preso l'argento individuale alle ultime olimpiadi, da questo matrimonio non può che nascere un super-arciere!!
venerdì 10 ottobre 2008
Strazio o disperazione?
Dopo la mia avventura di non-ricarica della tessera del treno (vedere Servizio o Strazio) ho vissuto l'ennesima situazione ridicola, a conferma ancora una volta di come non vi sia nessun interesse nel mantenere efficiente il servizio ferroviario locale.
Ieri, avendo la tessera ormai scarica, ho deciso di sfruttare la coincidenza di Formigine per scendere dal treno e ricaricare la tessera, risalendo poi regolarmente sul treno. E' una cosa che ho già fatto almeno tre volte in passato, sfruttando il fatto che il treno rimane fermo a Formigine per diversi minuti (aspettando quello in arrivo da Modena per lo scambio) e considerando che non vi è altro posto nelle vicinanze ove ricaricare la tessera. Arrivato a Formigine mi catapulto quindi giù dal treno, avviso il controllore delle mie intenzioni e gli chiedo di aspettare a ripartire; quest'ultimo annuisce. Corro verso la biglietteria e arrivato là chiedo che mi venga ricaricata la tessera. Il capostazione, in evidente stato di panico, mi dice che devo aspettare perché deve controllare l'arrivo del treno di Modena. Arriva il treno di Modena e il capostazione, anziché affrettarsi a ricaricarmi la tessera, con tutta calma inizia a scrivere dei dati su un registro. Io, già spazientito, gli faccio notare come debba risalire sul treno per Modena, e questi in tutta calma mi risponde che non faccio più in tempo perché il treno stava partendo. Guardo fuori e vedo attraverso i vetri del treno fermo sul binario il mio che si allontana. Apriti cielo!
Infuriato come non mai faccio notare al capostazione come avessi chiesto al controllore di aspettarmi, e di come questo servizio (ferroviario) sia veramente pessimo. Il capostazione inizia a farfugliare di come stia facendo del suo meglio e di come io avessi potuto prendermi un minuto in più, arrivare prima, e ricaricare la tessera con calma. Sempre più arrabbiato spiego al capostazione di come la sera prima mi sia stata rifiutata la ricarica per problemi di orario, e questi, sempre con calma, mi dice che sono le regole. Bene: allora che senso ha far circolare i treni fino a tardi (circa le 22) se la gente che torna a casa non ha il servizio di biglietteria? Ma inutile dire che il capostazione non capisce le mie argomentazioni, e continuando nella discussione mi rendo pure conto che non ha capito da dove provenissi: era infatti convinto fossi a terra e che dovessi salire sul treno per Modena dalla stazione di Formigine, non che fossi sceso dal treno diretto a Modena per risalirci. Gli rispiego la situazione e gli chiedo cortesemente di fornirmi il nome del controllore del treno. A questo punto il capostazione si rende conto del problema e, con il capo cosparso di cenere, mi conferma il cattivo comportamento del controllore, che quanto meno avrebbe dovuto informarmi di non scendere per problemi di tempo. Chiama quindi la stazione di Modena, si fa dire il nome del controllore e chiama poi quest'ultimo per sgridarlo sul suo comportamento. Chiaramente il controllore risponde nell'unico modo possibile: pensava che fossi già risalito. Eh si, perché di persone con un libro sottobraccio e lo zaino sulle spalle alle 18.30 nella stazione di Formigine ce ne sono tante...io non ne ho vista neanche una. E forse controllare che io fossi realmente salito o guardare dentro alla biglietteria per vedere se fossi ancora là era troppa fatica anche per il controllore.
Ad ogni modo non c'è niente da fare, se non aspettare il treno dopo (che passa con frequenza di un'ora) e fare reclamo...ma di sapere il nome del controllore non c'è modo, il capostazione si rifiuta di darmelo.
Dopo questa sfuriata in stazione mi sono rimboccato le maniche e sono tornato a casa a piedi, impiegandoci circa 30 minuti. Capisco benissimo che il treno, essendo un servizio pubblico, non può attendere i miei comodi (altrimenti sarebbe un taxi), ma effettivamente il controllore poteva anche fermarmi e il capostazione poteva servirmi subito. A parte questo, quello che mi fa realmente arrabbiare è che io ho perso il treno per voler essere onesto, ossia ricaricare la tessera per poter fare il biglietto. Chi me lo ha fatto fare? Non potevo far finta di nulla, rimanere a bordo seduto a leggere, e nel caso di un controllo dire che avevo la tessera esaurita e la stavo per ricaricare, o meglio ancora che la macchinetta non funzionava (scusa molto in voga fra gli extra-comunitari)? Dopotutto da Settembre ad oggi (circa 30 viaggi) ho avuto solo tre controlli (ossia il 10%). Come ho detto con il capostazione, che razza di servizio stanno mantenendo?
Ah, questa mattina ho potuto fare il biglietto regolarmente....
Ieri, avendo la tessera ormai scarica, ho deciso di sfruttare la coincidenza di Formigine per scendere dal treno e ricaricare la tessera, risalendo poi regolarmente sul treno. E' una cosa che ho già fatto almeno tre volte in passato, sfruttando il fatto che il treno rimane fermo a Formigine per diversi minuti (aspettando quello in arrivo da Modena per lo scambio) e considerando che non vi è altro posto nelle vicinanze ove ricaricare la tessera. Arrivato a Formigine mi catapulto quindi giù dal treno, avviso il controllore delle mie intenzioni e gli chiedo di aspettare a ripartire; quest'ultimo annuisce. Corro verso la biglietteria e arrivato là chiedo che mi venga ricaricata la tessera. Il capostazione, in evidente stato di panico, mi dice che devo aspettare perché deve controllare l'arrivo del treno di Modena. Arriva il treno di Modena e il capostazione, anziché affrettarsi a ricaricarmi la tessera, con tutta calma inizia a scrivere dei dati su un registro. Io, già spazientito, gli faccio notare come debba risalire sul treno per Modena, e questi in tutta calma mi risponde che non faccio più in tempo perché il treno stava partendo. Guardo fuori e vedo attraverso i vetri del treno fermo sul binario il mio che si allontana. Apriti cielo!
Infuriato come non mai faccio notare al capostazione come avessi chiesto al controllore di aspettarmi, e di come questo servizio (ferroviario) sia veramente pessimo. Il capostazione inizia a farfugliare di come stia facendo del suo meglio e di come io avessi potuto prendermi un minuto in più, arrivare prima, e ricaricare la tessera con calma. Sempre più arrabbiato spiego al capostazione di come la sera prima mi sia stata rifiutata la ricarica per problemi di orario, e questi, sempre con calma, mi dice che sono le regole. Bene: allora che senso ha far circolare i treni fino a tardi (circa le 22) se la gente che torna a casa non ha il servizio di biglietteria? Ma inutile dire che il capostazione non capisce le mie argomentazioni, e continuando nella discussione mi rendo pure conto che non ha capito da dove provenissi: era infatti convinto fossi a terra e che dovessi salire sul treno per Modena dalla stazione di Formigine, non che fossi sceso dal treno diretto a Modena per risalirci. Gli rispiego la situazione e gli chiedo cortesemente di fornirmi il nome del controllore del treno. A questo punto il capostazione si rende conto del problema e, con il capo cosparso di cenere, mi conferma il cattivo comportamento del controllore, che quanto meno avrebbe dovuto informarmi di non scendere per problemi di tempo. Chiama quindi la stazione di Modena, si fa dire il nome del controllore e chiama poi quest'ultimo per sgridarlo sul suo comportamento. Chiaramente il controllore risponde nell'unico modo possibile: pensava che fossi già risalito. Eh si, perché di persone con un libro sottobraccio e lo zaino sulle spalle alle 18.30 nella stazione di Formigine ce ne sono tante...io non ne ho vista neanche una. E forse controllare che io fossi realmente salito o guardare dentro alla biglietteria per vedere se fossi ancora là era troppa fatica anche per il controllore.
Ad ogni modo non c'è niente da fare, se non aspettare il treno dopo (che passa con frequenza di un'ora) e fare reclamo...ma di sapere il nome del controllore non c'è modo, il capostazione si rifiuta di darmelo.
Dopo questa sfuriata in stazione mi sono rimboccato le maniche e sono tornato a casa a piedi, impiegandoci circa 30 minuti. Capisco benissimo che il treno, essendo un servizio pubblico, non può attendere i miei comodi (altrimenti sarebbe un taxi), ma effettivamente il controllore poteva anche fermarmi e il capostazione poteva servirmi subito. A parte questo, quello che mi fa realmente arrabbiare è che io ho perso il treno per voler essere onesto, ossia ricaricare la tessera per poter fare il biglietto. Chi me lo ha fatto fare? Non potevo far finta di nulla, rimanere a bordo seduto a leggere, e nel caso di un controllo dire che avevo la tessera esaurita e la stavo per ricaricare, o meglio ancora che la macchinetta non funzionava (scusa molto in voga fra gli extra-comunitari)? Dopotutto da Settembre ad oggi (circa 30 viaggi) ho avuto solo tre controlli (ossia il 10%). Come ho detto con il capostazione, che razza di servizio stanno mantenendo?
Ah, questa mattina ho potuto fare il biglietto regolarmente....
giovedì 9 ottobre 2008
Servizio o strazio?
Ieri sera mi sono recato in stazione a Formigine per ricaricare la mia tessera del treno, ebbene non mi è stato possibile ricaricarla perché oltre le 19.30 il servizio di ricarica non è più attivo. Chissà che senso ha far circolare i treni fin verso le 21 se i servizi di biglietteria/ricarica sono sospesi dalle 19.30. Una persona che si accorga, rientrando a casa la sera, di avere la tessera scarica e decida di fermarsi in stazione (perché è di strada) per ricaricarla si sentirà rispondere, come è successo a me, che deve ripassare il giorno seguente in un orario differente.
E pensare che un paio di mesi fa l'avevo ricaricata proprio prima di andare in piscina, è forse questo un nuovo disservizio del sistema ferroviario locale?
Inizio ad essere fermamente convinto che la regione voglia far chiudere questa tratta di treno. Da quando è subentrata la regione non ci sono più controlli (non che prima abbondassero, ma qualcuno c'era), gli orari sono cambiati, la frequenza dei treni diminuita, le fermate ridotte e...non si può caricare nemmeno la propria tessera.
Finirà che riprenderemo tutti la macchina, e che continueremo a lamentarci del traffico e dell'inquinamento.
E pensare che un paio di mesi fa l'avevo ricaricata proprio prima di andare in piscina, è forse questo un nuovo disservizio del sistema ferroviario locale?
Inizio ad essere fermamente convinto che la regione voglia far chiudere questa tratta di treno. Da quando è subentrata la regione non ci sono più controlli (non che prima abbondassero, ma qualcuno c'era), gli orari sono cambiati, la frequenza dei treni diminuita, le fermate ridotte e...non si può caricare nemmeno la propria tessera.
Finirà che riprenderemo tutti la macchina, e che continueremo a lamentarci del traffico e dell'inquinamento.
venerdì 3 ottobre 2008
Problema lettura file di proprietà in Eclipse
Qualche giorno fa ho ripristinato il workspace di Eclipse 3.3 per una nuova installazione di Eclipse 3.4, ma il riavvio di un progetto Java mi ha causato qualche problema. In particolare mi sono trovato la seguente eccezione:
leggendo un file di proprietà Java in formato XML. Ho ricontrollato il classpath e le librerie erano tutte al loro posto, quindi mi è stato un po' difficile individuare il problema. Ho aggiornato Xerces, ho provato a copiarne diverse versioni ma niente. Infine qualcuno sul forum della Sun mi ha indicato la soluzione: Java 6 viene distribuito con la sua versione di Xerces, e quindi forzare l'utilizzo di una versione differente può creare alcuni problemi di compatibilità. Basta rimuovere allora i package di Xerces dal classpath per risolvere il problema.
java.lang.ClassCastException: org.apache.xerces.dom.DeferredCommentImpl cannot be cast to org.w3c.dom.Element
ERROR - Cannot load properties from the specified file <./conf/login.prop> java.lang.ClassCastException: org.apache.xerces.dom.DeferredCommentImpl cannot be cast to org.w3c.dom.Element
at java.util.XMLUtils.importProperties(XMLUtils.java:97)
at java.util.XMLUtils.load(XMLUtils.java:69)
at java.util.Properties.loadFromXML(Properties.java:852)
at g2.utility.HRPMProperties.(HRPMProperties.java:78)
at g2.utility.HRPMProperties.getInstance(HRPMProperties.java:94)
at g2.gui.workers.ApplicationSwingWorker.(ApplicationSwingWorker.java:36)
at g2.main.Main.main(Main.java:37)
leggendo un file di proprietà Java in formato XML. Ho ricontrollato il classpath e le librerie erano tutte al loro posto, quindi mi è stato un po' difficile individuare il problema. Ho aggiornato Xerces, ho provato a copiarne diverse versioni ma niente. Infine qualcuno sul forum della Sun mi ha indicato la soluzione: Java 6 viene distribuito con la sua versione di Xerces, e quindi forzare l'utilizzo di una versione differente può creare alcuni problemi di compatibilità. Basta rimuovere allora i package di Xerces dal classpath per risolvere il problema.
giovedì 2 ottobre 2008
Communicating thru Intenet
It's amazing how easy communicating thru Internet is. Just as an example yesterday I got a contact from Rick McKinney, an archer myth for myself! This is just the last important and/or famous person I met thru Internet, and in fact in the past I got contact with a lot of important developers (from PostgreSQL to Samba and Linux....).
This is one of the things I like the most about Internet: it does not matter who you are or what you do, you can always and easily meet people you only heard about!
This is one of the things I like the most about Internet: it does not matter who you are or what you do, you can always and easily meet people you only heard about!
WhiteCat: injecting roles into Java agents/proxies
In the past few months I developed the prototype of a role system for Java agents that I called WhiteCat, in contrast to RoleX (also known as BlackCat).
The prototype is developed in 100% Java and is based, as its precedessor, on the Javassist bytecode manipulation library. The idea is the same as in RoleX: Java agents should be enhanced thru roles (i.e., Java third party libraries) dynamically at run-time, and must be merged with the role they assume, becoming a single entity with their roles. The aim is thus to support role external visibility, that is the capability to recognize a role played by an agent simply looking at it. Since in Java "looking" at an object and retrieving its class information, the WhiteCat approach must manipulate the agent class structure in order to make the role visible as a part of the agent itself.
For a more detailed explaination of the inspiration behind this role approach please see this article on the IBM Systems Journal.
There are a few drawbacks in the RoleX design that lead me to the design of the WhiteCat approach:
Starting from the above drawbacks I decide to design a new approach with the same base concepts, but faster, simpler and with more role visibility options. The result is the WhiteCat prototype that provides three level of role visibility:

Role visibility is defined thru interfaces and annotations, so that the role loader can recognize how and where to apply changes to the agent (or its proxy).
Moreover WhiteCat allows the manipulation of either the agent class structure or its proxy one. In the case the agent is hidden behind a proxy, and the role is visible or public, the proxy class structure is changed in order to make the role perceivable; in the case the role is directly accessible (i.e., there's no proxy) its class structure is directly changed in order to apply changes.
As an example consider the following application snippet:
As you can see the agent proxy is simply injected with the role. Please note that a role instance is used, not a role class. This means that the role can be instantiated and initialized as you like, and can injected to the agent or its proxy when you want, and of course the role will keep its state.
Just after the injectPublicRole() call, the agent proxy is perceivable (thru instanceof) as implementing the public role interface, that in the above example is the IDatabaseAdministrator one. In order to achieve this, the agent proxy class structure is extended by the role one, meaning that it is like the agent proxy has new subclasses with the role properties. Since the agent proxy class structure is extended (i.e., all the classes up to the agent proxy are not touched), there's no need to discard the "old" object reference. If the developer does not use the new proxy reference (i.e., newproxy in the code above), it will simply not be able to exploit role capabilities, but he will be able to exploit all
original proxy capabilities.
The RoleEngine is a special class loader that performs bytecode manipulation in order to extend the agent proxy class chain. The RoleEngine exploits the Javassist library in order to manipulate the class structure, and appends
to each new class a unique number, so that the same class can be manipulated different times by the same RoleLoader as the result will have a different name and so will not clashes with other already manipulated classes. Moreover the role adoption model is simpler than in RoleX, since the developers will handle roles in straight way: once the injectPublicRole() is called, the developer could
test the agent proxy against the injected role and cast the agent proxy to such role. Last but not least, since WhiteCat does not manipulate a whole inheritance chain, rather it appends a chain to another, the approach is much faster than the RoleX one.
Of course, as shown in the figure, the manipulation process can be repeated as many times as needed (i.e., one for every role assumption).

In my opinion WhiteCat represents a very enhanced role approach than RoleX, and even if still a prototype, it is enough stable to be used in role based applications.
I'm still working on WhiteCat, and I will release it under the GNU GPLv3 license. If you are interested in WhiteCat and want to know more details or discuss with me, please e-mail me (fluca1978 at gmail.com) and I will be happy to provide more information.
I'd like to thanks Mr. Shigeru Chiba and the JBoss team and community for their work and support on Javassist.
The prototype is developed in 100% Java and is based, as its precedessor, on the Javassist bytecode manipulation library. The idea is the same as in RoleX: Java agents should be enhanced thru roles (i.e., Java third party libraries) dynamically at run-time, and must be merged with the role they assume, becoming a single entity with their roles. The aim is thus to support role external visibility, that is the capability to recognize a role played by an agent simply looking at it. Since in Java "looking" at an object and retrieving its class information, the WhiteCat approach must manipulate the agent class structure in order to make the role visible as a part of the agent itself.
For a more detailed explaination of the inspiration behind this role approach please see this article on the IBM Systems Journal.
There are a few drawbacks in the RoleX design that lead me to the design of the WhiteCat approach:
- RoleX merges the role in the agent changing the whole agent class structure. This means that not only the bottom of the agent class inheritance chain is modified, but that each level of the agent inheritance is changed depending on the role class structure. This is a time consuming activity.
- RoleX requires a different class loader for each role assumption/release. This means that if the same agent assumes different roles at different times, each assumption requires a different class loader (called role loader). This is resource consuming.
- RoleX requires developers to deal with reflection and invocation translators to make injected features (i.e., role features) available. This is complex to understand and to develop/mantain.
- RoleX provides only one kind of role, that is a publicly visible role. Each assumed role is automatically visible to external entities, and this could lead to security and privacy problems.
- RoleX injects the role into the agent class, without taking into account that the agent could be hidden behind a proxy (see for example Aglets), and thus the role external visibility is not exploitable.
- RoleX requires the role to be not instantiated and used by anything that is not the role loader. In other words you are not free to create a role object, since the role engine will workonly with the role classes, and thus having a role object will not provide you any meaningful capability.
- RoleX creates different class definitions at run-time, so you could have two classes with the same name and different implementation. It can thus be difficult to deal with objects, since you could not knowor recognize which one is the original (i.e., never manipulated) one. Moreover, this way of working requires that developers discard the old (i.e., not manipulated) agent reference and use the new one provided by the role engine. Of course, there is no way to enforce this practice, so a malicious developer could keep a reference to both.
Starting from the above drawbacks I decide to design a new approach with the same base concepts, but faster, simpler and with more role visibility options. The result is the WhiteCat prototype that provides three level of role visibility:
- invisible: the role is not visible at all from an external point of view. This means that an agent has assumed and uses a role without letting any other agent to be able to autonomously knowing it;
- visible: the role is visible to any external entity;
- public: the role is visible and can even be used from external entities.

Role visibility is defined thru interfaces and annotations, so that the role loader can recognize how and where to apply changes to the agent (or its proxy).
Moreover WhiteCat allows the manipulation of either the agent class structure or its proxy one. In the case the agent is hidden behind a proxy, and the role is visible or public, the proxy class structure is changed in order to make the role perceivable; in the case the role is directly accessible (i.e., there's no proxy) its class structure is directly changed in order to apply changes.
As an example consider the following application snippet:
// role class
Class roleClass = root.loadClass("whitecat.example.DatabaseAdministrator");
DatabaseAdministrator dbaRole = (DatabaseAdministrator) roleClass.newInstance();
AgentProxy proxy = .... // get the proxy in the way your platform allows you
// get a new role loader engine
RoleEngine engine = new RoleEngine();
// add the dbarole to the current agent
AgentProxy newproxy = engine.injectPublicRole(proxy, dbaRole);
if( newproxy instanceof IDatabaseAdministrator ) {
// the proxy can work as a IDatabaseAdministrator object from here!
}
As you can see the agent proxy is simply injected with the role. Please note that a role instance is used, not a role class. This means that the role can be instantiated and initialized as you like, and can injected to the agent or its proxy when you want, and of course the role will keep its state.
Just after the injectPublicRole() call, the agent proxy is perceivable (thru instanceof) as implementing the public role interface, that in the above example is the IDatabaseAdministrator one. In order to achieve this, the agent proxy class structure is extended by the role one, meaning that it is like the agent proxy has new subclasses with the role properties. Since the agent proxy class structure is extended (i.e., all the classes up to the agent proxy are not touched), there's no need to discard the "old" object reference. If the developer does not use the new proxy reference (i.e., newproxy in the code above), it will simply not be able to exploit role capabilities, but he will be able to exploit all
original proxy capabilities.
The RoleEngine is a special class loader that performs bytecode manipulation in order to extend the agent proxy class chain. The RoleEngine exploits the Javassist library in order to manipulate the class structure, and appends
to each new class a unique number, so that the same class can be manipulated different times by the same RoleLoader as the result will have a different name and so will not clashes with other already manipulated classes. Moreover the role adoption model is simpler than in RoleX, since the developers will handle roles in straight way: once the injectPublicRole() is called, the developer could
test the agent proxy against the injected role and cast the agent proxy to such role. Last but not least, since WhiteCat does not manipulate a whole inheritance chain, rather it appends a chain to another, the approach is much faster than the RoleX one.
Of course, as shown in the figure, the manipulation process can be repeated as many times as needed (i.e., one for every role assumption).

In my opinion WhiteCat represents a very enhanced role approach than RoleX, and even if still a prototype, it is enough stable to be used in role based applications.
I'm still working on WhiteCat, and I will release it under the GNU GPLv3 license. If you are interested in WhiteCat and want to know more details or discuss with me, please e-mail me (fluca1978 at gmail.com) and I will be happy to provide more information.
I'd like to thanks Mr. Shigeru Chiba and the JBoss team and community for their work and support on Javassist.
martedì 30 settembre 2008
MIgrare la posta da kmail 1.9 a kmail 1.10
Con l'avvento del KDE 4.1 è stato reso finalmente disponibile la versione stabile del nuovo kmail, la 1.10. Peccato che migrare la posta e le impostazioni dalle versioni precedenti non è una cosa semplice, e infatti sono stati necessari diversi passaggi tutti fatti per tentativi e non documentati sul sito web del progetto. Si suppone di avere la configurazione della vecchia versione di kmail sotto la directory ~/.kde e di avere la nuova configurazione (quella verso cui migrare) nella directory ~/.kde4. Anzitutto è bene fare un backup della propria posta (~/.kde/share/apps/kmail/mail) come sempre, prima di procedere a qualsiasi migrazione di dati.
Di seguito i passi da effettuare:
Di seguito i passi da effettuare:
- migrazione della posta: copiare o spostare la directory ~/.kde/share/apps/kmail/mail nel relativo percorso della nuova installazione ~/.kde4/share/apps/kmail/mail.
- migrare le impostazioni: vanno spostati i file ~/.kde/share/config/kmailrc, ~/.kde/share/config/emaildefaults, ~/.kde/share/config/identities.
- definire le fonti di trasporto (server in uscita): è necessario definitre il file ~/.kde4/config/mailtransport e copiare al suo interno le sezioni [Transport N] (N = numero di trasporto) originariamente presenti nel vecchio file di configurazione kmailrc.
- definire i server di ricezione (account): occorre controllare che il numero delle sezioni [Account N] (N = numero di account) contenga gli account corretti e che ci sia una voce nella sezione [General] una voce accounts con valore pari al massimo numero di account N presente nel file. Si presti attenzione che se il Type=Pop è scritto con 'pop' minuscolo (come nella vecchia versione, kmail si limiterà a cancellare gli account (che gli risultano sconosciuti) dal file di configurazione!
- sostituire i vecchi percorsi: cambiare i vecchi percorsi di posta da ~/.kde/share/apps/kmail/mail a ~/.kde4/share/apps/kmail/mail.
BlockSite
Mi è capitato di dover fare una installazione di computer ad una fiera, dove solo una parte all'interno di un sito doveva essere visibile. Solitamente quando era necessario bloccare determinati sit usavo il trucco di impostare nel browser web un proxy fittizio e di imporre il non utilizzo del proxy per i domini sbloccati. Ma per rendere accessibile solo la parte di un sito ho dovuto installare una estensione apposita di Mozilla Firefox: BlockSite. Tramite questo strumento è possibile impostare una lista di URL come whitelist o blacklist (nel mio caso whitelist), e quindi stabilire effettivamente quali URL possono essere accessibili e quali bloccati.
Nel mio caso specifico è stato sufficiente impostare nelle preferenze di BlockSite gli URL da sbloccare (whitelist) senza specificare nulla nella blacklist (quindi avendo bloccati tutti i siti), e di rimuovere il warning utente per i siti bloccati (questo per non infastidire i navigatori). Il risultato è che chiunque provi a navigare al di fuori della whitelist non ci riesce, e nessun errore viene visualizzato: semplicemente il browser web non si sposta dalla pagina correntemente caricata (quindi dall'URL in whitelist).
Nel mio caso specifico è stato sufficiente impostare nelle preferenze di BlockSite gli URL da sbloccare (whitelist) senza specificare nulla nella blacklist (quindi avendo bloccati tutti i siti), e di rimuovere il warning utente per i siti bloccati (questo per non infastidire i navigatori). Il risultato è che chiunque provi a navigare al di fuori della whitelist non ci riesce, e nessun errore viene visualizzato: semplicemente il browser web non si sposta dalla pagina correntemente caricata (quindi dall'URL in whitelist).
Allenamenti indoor
Lunedì
Tornato dal Cersaie, prima di andare in piscina mi sono fermato al campo per fare qualche tiro, e così ho fatto 40 frecce a 18 mt su bersaglio Las Vegas. Ancora una volta, tenendo la corda con l'anulare ho frecce che impattano a destra e rosate abbastanza strette, ma dopo circa 20 frecce forse per stanchezza sulle dita cominciano a comparire errori a sinistra. Ho anche cercato di tenere le scapole maggiormente aperte in fase di trazione, ma non è affatto semplice poiché una trazione lineare come quella che ho provoca facilmente una compressione della schiena. Questa è sicuramente una cosa sulla quale vale la pena fare qualche esperimento.
Martedì
Ancora 40 frecce a 18 mt di ritorno dal Cersaie. Aprire di più la schiena allontanando le scapole mi riesce difficile, però negli ultimi tiri sono riuscito a rilassare gli antagonisti della spalla destra, e questo mi pare un buon segno. Ancora una volta però dopo circa 20 frecce inizio ad avere errori a sinistra, colpa un po' dell'anulare che non tiene e di un tiro un po' più deciso che mi produce qualche esplosione del braccio davanti. Ho dovuto tirtare con la patella della soma al posto di quella cavalier perché la prima ha la pelle leggermente più dura. e avendo un taglio sull'indice mi riusciva difficile tenere la corda.
Tornato a casa ho fatto qualche trazione per cercare di comprendere meglio come rilassare gli antagonisti, ma mi sento ancora lontano dal risultato. Se non altro inizio a capire, o meglio ad intuire la strada da seguire.
Mercoledì
Solo qualche trazione a casa prima e dopo la piscina, per cercare di esercitarmi sul rilassamento degli antagonisti della spalla desttra. Ho anche fatto delle prove con i flettenti più morbidi al fine di poter meglio controllare il movimento. Quello che ho scoperto è che avendo una trazione fluida, con qualche brandeggio leggermente verso il basso per poi salire al mento o laterale mi aiuta ad arrivare in ancoraggio ben disteso e rilassato. Ovviamente tutte cose da riprovare e ripetere sul campo. La parola chiave comunque è trazione fluida, è inutile fossilizzarsi su una trazione rigida e cercare di rilassare le spalle ad ancoraggio avvenuto.
Giovedì
48 frecce a 18 mt, devo dire che ho ripreso ad andare molto a sinistra, ma mi sto concentrando sulla fluidità del movimento e non riesco a tenere bene con l'anulare. Il gesto inizia ad essere più fluido, ma ancora mi ci vuole molto per memorizzare il movimento. A casa ho poi fatto qualche altra trazione per meglio allenare la memoria muscolare. In sostanza riesco a fare qualche tiro molto sciolto, ben rilassato e quindi stabile. Dalle prove che ho fatto direi che si tratti anche di rilassare la spalla destra al momento della precarica, posizionandola ben allineata da subito in modo da facilatarne l'incastro una volta in ancoraggio. Sembra inoltre che un lieve brandeggio laterale o verticale possa facilitare il posizionamento con la schiena ben aperta. E' come se arrivando diretto in ancoraggio mi fermassi in leggero sotto-allungo (dal punto di vista delle spalle) e sia costretto a gonfiarmi per uscire poi dal clicker.
E il campo?
Sono un po' contrariato per essere stato sospeso (in senso buono) dall'uso del campo di appoggio. Infatti non posso andare al campo per il periodo invernale fino a quando non si sarà fatto un consiglio, e il problema da quello che sembra è comune un po' a tutte le società. Non resta che aspettare....
Martedì
45 frecce a 18 mt al campo della Re Astolfo, ahimé terminate al buio perché ormai non si riesce più a tirare all'aperto uscendo dall'ufficio. Qualche errore a sinistra, ma meglio che nei precedenti allenamenti. Ancora difficoltà invece nello stabilizzare il tiro, è come se ad ogni allenamento mi trovassi a scoprire nuove posizioni che sembrano darmi stabilità. Voglio fare qualche esperimento con le trazioni a casa.
Sabato
63 frecce a 18 mt al campo. Ho ancora dei grossi errori laterali, ma il tiro inizia ad essere più stabile. Cerco nella precarica di rilassare ed estendere bene la spalla della corda, in modo da avere una posizione più solida e ancoraggio, e in effetti qualche risultato lo noto. Per il momento sto facendo delle trazioni a casa, visto che non ho accesso ad un campo vicino. Inoltre, da un esperimento nell'ultima voléé, parte degli errori laterali potrebbe essere dovuto ad un errore di visione, poiché ho notato che tirando con gli occhiali da sole (sole contro) andavo tutto a destra, e senza (con occhio sinistro chiuso) in centro. Devo approfondire questa cosa facendo delle prove e tenendo l'occhio sinistro chiuso.
Mi rincuora che il mio allenatore dica che sto tirando bene, penso sia solo questione di tempo (e di sicurezza) prima che qualche punto inizi a ritornare.
Tornato dal Cersaie, prima di andare in piscina mi sono fermato al campo per fare qualche tiro, e così ho fatto 40 frecce a 18 mt su bersaglio Las Vegas. Ancora una volta, tenendo la corda con l'anulare ho frecce che impattano a destra e rosate abbastanza strette, ma dopo circa 20 frecce forse per stanchezza sulle dita cominciano a comparire errori a sinistra. Ho anche cercato di tenere le scapole maggiormente aperte in fase di trazione, ma non è affatto semplice poiché una trazione lineare come quella che ho provoca facilmente una compressione della schiena. Questa è sicuramente una cosa sulla quale vale la pena fare qualche esperimento.
Martedì
Ancora 40 frecce a 18 mt di ritorno dal Cersaie. Aprire di più la schiena allontanando le scapole mi riesce difficile, però negli ultimi tiri sono riuscito a rilassare gli antagonisti della spalla destra, e questo mi pare un buon segno. Ancora una volta però dopo circa 20 frecce inizio ad avere errori a sinistra, colpa un po' dell'anulare che non tiene e di un tiro un po' più deciso che mi produce qualche esplosione del braccio davanti. Ho dovuto tirtare con la patella della soma al posto di quella cavalier perché la prima ha la pelle leggermente più dura. e avendo un taglio sull'indice mi riusciva difficile tenere la corda.
Tornato a casa ho fatto qualche trazione per cercare di comprendere meglio come rilassare gli antagonisti, ma mi sento ancora lontano dal risultato. Se non altro inizio a capire, o meglio ad intuire la strada da seguire.
Mercoledì
Solo qualche trazione a casa prima e dopo la piscina, per cercare di esercitarmi sul rilassamento degli antagonisti della spalla desttra. Ho anche fatto delle prove con i flettenti più morbidi al fine di poter meglio controllare il movimento. Quello che ho scoperto è che avendo una trazione fluida, con qualche brandeggio leggermente verso il basso per poi salire al mento o laterale mi aiuta ad arrivare in ancoraggio ben disteso e rilassato. Ovviamente tutte cose da riprovare e ripetere sul campo. La parola chiave comunque è trazione fluida, è inutile fossilizzarsi su una trazione rigida e cercare di rilassare le spalle ad ancoraggio avvenuto.
Giovedì
48 frecce a 18 mt, devo dire che ho ripreso ad andare molto a sinistra, ma mi sto concentrando sulla fluidità del movimento e non riesco a tenere bene con l'anulare. Il gesto inizia ad essere più fluido, ma ancora mi ci vuole molto per memorizzare il movimento. A casa ho poi fatto qualche altra trazione per meglio allenare la memoria muscolare. In sostanza riesco a fare qualche tiro molto sciolto, ben rilassato e quindi stabile. Dalle prove che ho fatto direi che si tratti anche di rilassare la spalla destra al momento della precarica, posizionandola ben allineata da subito in modo da facilatarne l'incastro una volta in ancoraggio. Sembra inoltre che un lieve brandeggio laterale o verticale possa facilitare il posizionamento con la schiena ben aperta. E' come se arrivando diretto in ancoraggio mi fermassi in leggero sotto-allungo (dal punto di vista delle spalle) e sia costretto a gonfiarmi per uscire poi dal clicker.
E il campo?
Sono un po' contrariato per essere stato sospeso (in senso buono) dall'uso del campo di appoggio. Infatti non posso andare al campo per il periodo invernale fino a quando non si sarà fatto un consiglio, e il problema da quello che sembra è comune un po' a tutte le società. Non resta che aspettare....
Martedì
45 frecce a 18 mt al campo della Re Astolfo, ahimé terminate al buio perché ormai non si riesce più a tirare all'aperto uscendo dall'ufficio. Qualche errore a sinistra, ma meglio che nei precedenti allenamenti. Ancora difficoltà invece nello stabilizzare il tiro, è come se ad ogni allenamento mi trovassi a scoprire nuove posizioni che sembrano darmi stabilità. Voglio fare qualche esperimento con le trazioni a casa.
Sabato
63 frecce a 18 mt al campo. Ho ancora dei grossi errori laterali, ma il tiro inizia ad essere più stabile. Cerco nella precarica di rilassare ed estendere bene la spalla della corda, in modo da avere una posizione più solida e ancoraggio, e in effetti qualche risultato lo noto. Per il momento sto facendo delle trazioni a casa, visto che non ho accesso ad un campo vicino. Inoltre, da un esperimento nell'ultima voléé, parte degli errori laterali potrebbe essere dovuto ad un errore di visione, poiché ho notato che tirando con gli occhiali da sole (sole contro) andavo tutto a destra, e senza (con occhio sinistro chiuso) in centro. Devo approfondire questa cosa facendo delle prove e tenendo l'occhio sinistro chiuso.
Mi rincuora che il mio allenatore dica che sto tirando bene, penso sia solo questione di tempo (e di sicurezza) prima che qualche punto inizi a ritornare.
domenica 28 settembre 2008
PL>Y Modena
Venerdì sera ho visitato PL>Y, la fiera del gioco organizzata a Modena. Devo dire che l'organizzazione ha fatto veramente un bel lavoro, lo spazio è ben allestito con video games, wii, bigliardini, tavoli per giochi di società, fumetti, e due piste di macchinine giganti! Insomma, veramente una buona impressione, complimenti agli organizzatori.
Con i miei amici abbiamo anche giocato ad un gioco da tavolo, Thurn und Taxi, basato su corse in diligenza. All'inizio è stata un po' dura capire le regole (spiegate dal personale di PL>Y), ma una volta comprese devo dire che ho trovato il gioco piuttosto affascinante.
Con i miei amici abbiamo anche giocato ad un gioco da tavolo, Thurn und Taxi, basato su corse in diligenza. All'inizio è stata un po' dura capire le regole (spiegate dal personale di PL>Y), ma una volta comprese devo dire che ho trovato il gioco piuttosto affascinante.
venerdì 26 settembre 2008
Programma PGDay 2008
Il programma del PGDay 2008 è on-line: http://www.pgday.org/it/programma. Quest'anno ci saranno 28 fra talk e mini-corsi, italiani e inglesi, per due giorni pieni di PostgreSQL!
mercoledì 24 settembre 2008
Azzerare il contenuto di un disco o di una chiavetta USB
Cancellare il contenuto di un disco portatile o di una chiavetta usb con Linux è un gioco da ragazzi: basta dare un comando simile al seguente (essende sdb1 la partizione corrispondente che deve essere cancellata)
e il dispositivo sarà riempito di zeri. Questo non significa che il dispositivo conterrà degli '0' leggibili, ma che tutto il file system risulterà inestitente, e che quindi anche montare il dispositivo non riuscirà fino a quando non verrà nuovamente formattato il dispositivo stesso.
sudo dd if=/dev/zero of=/dev/sdb1
e il dispositivo sarà riempito di zeri. Questo non significa che il dispositivo conterrà degli '0' leggibili, ma che tutto il file system risulterà inestitente, e che quindi anche montare il dispositivo non riuscirà fino a quando non verrà nuovamente formattato il dispositivo stesso.
lunedì 22 settembre 2008
AgorArco chiude?
Stamattina ho effettuato il login al forum AgorArco poiché volevo sottoporre una domanda, ma subito il layout mi ha fatto intuire che ci fosse qualche cosa che non andava: l'indice dei forum era riferito alle sole sezioni di acquisto/vendita, mancavano tutte le sezioni relative ai materiali, alla tecnica di tiro, ecc.
Ho pensato ci fosse una qualche operazione di manutenzione in corso, e ho quindi deciso di attendere.
Più tardi ho riprovato, ma la situazione non era cambiata, così ho guardato fra i messaggi degli amministratori ed ho trovato un messaggio di ieri che dice che il forum è chiuso e che tutti i messaggi al di fuori delle sopra citate sezioni non sono permessi (infatti non ho più nemmeno la lista dei messaggi che ho inviato nelle mie impostazioni). Il messaggio in particolare dice che:
Ora la decisione è piuttosto drastica, se si conta anche l'elevato numero di messaggi che il forum gestiva, ma soprattutto non si ha alcuna spiegazione concreta dei motivi dietro a questa chiusura. Se esistono motivi personali perché l'amministrazione del forum non possa continuare allora è bene piuttosto cercare nuovi amministratori e lasciare il servizio fruibile. Altrimenti ritengo che gli amministratori debbano fornire spiegazioni circa il loro atteggiamento.
Ho pensato ci fosse una qualche operazione di manutenzione in corso, e ho quindi deciso di attendere.
Più tardi ho riprovato, ma la situazione non era cambiata, così ho guardato fra i messaggi degli amministratori ed ho trovato un messaggio di ieri che dice che il forum è chiuso e che tutti i messaggi al di fuori delle sopra citate sezioni non sono permessi (infatti non ho più nemmeno la lista dei messaggi che ho inviato nelle mie impostazioni). Il messaggio in particolare dice che:
I motivi della chiusura del forum sono privati ed estranei allo sport e al tiro con l'arco e pertanto non possono essere riportati.
Ora la decisione è piuttosto drastica, se si conta anche l'elevato numero di messaggi che il forum gestiva, ma soprattutto non si ha alcuna spiegazione concreta dei motivi dietro a questa chiusura. Se esistono motivi personali perché l'amministrazione del forum non possa continuare allora è bene piuttosto cercare nuovi amministratori e lasciare il servizio fruibile. Altrimenti ritengo che gli amministratori debbano fornire spiegazioni circa il loro atteggiamento.
Iscriviti a:
Post (Atom)